
Merging Tables
Introduction
DITA Merge currently supports CALS, HTML, and DITA simple table processing.
The CALS table processing ensures that when syntactically and semantically valid (as per OASIS CALS table model documentation) input tables are provided the result will be a valid CALS table. Similarly, the HTML tables processing ensures that when valid input tables are provided - according to the HTML 4 or HTML 5 documentation - the result will be a valid HTML 4/5 table. Note that both inputs need to follow the same standard (i.e. be HTML 4 or HTML 5).
In the release 11.0.0, DITA Merge has two table processing algorithms. We have recently implemented a table processing algorithm version 2.
By default, DITA Merge will run with table processing algorithm version 1 with an option to switch to version 2. Please note that table processing algorithm version 2 will be used by default in the future releases.
Following sections outline the two algorithm along with their API settings.
Table processing algorithm version 1
DITA Merge processes tables defined in the XML input in a special way considering its structure while keeping the table comparison result valid. Some type of changes such as table entries overlapping or spanning multiple rows and columns are difficult to represent at fine granularity, whilst ensuring validity. In these cases, the changes are represented at row (i.e. groups of added/deleted rows) or even whole-table granularity. In case of DITA simple tables, the syntactic constraints ensure that cells cannot overlap or span either rows or columns, therefore changes are represented at a fine grain level of detail.
This approach was roughly based on 2 techniques and stemmed partly from the goal that it should be possible to reconstruct both A and B documents from the result:
Keying cells according to the column to which they came from in sequence.
Where there are structure changes, such as a span in one input that’s not there in another, it’s not possible to show both A and B so the idea was to show separate A and B rows or even tables.
Configuration
In DITA Merge, CALS tables and HTML table processing are configured separately. The following section talks about how to turn table processing on and off and set different CALS table processing modes.
The following section describes the table configuration settings for the ConcurrentMerge class. Similar table configuration settings are also available for the SequentialMerge class.
CALS tables
CALS table processing is enabled/disabled using setCalsTableProcessing.
HTML tables
HTML table processing is enabled/disabled using setHtmlTableProcessing.
Invalid table behaviour
In order to ensure that only valid tables are passed to our specialised CALS table processing, each input table is marked either valid or invalid. This parameter declares what type of processing should be used for those tables that are marked as invalid. The 'warning report mode' parameter configures how recoverable errors are reported.
Three options are provided:
FAIL: The fail option stops the comparison by throwing an appropriate exception (that includes the errors identified by the validity checker).
PROPAGATE_UP: The propagate up option ensures that changes to an invalid table (or more specifically
tgroup) are represented at the table level.COMPARE_AS_XML : The compare as XML option essentially compares the tables as if they were well-formed XML.
This can be configured using setInvalidTableBehaviour.
Warning report mode
This mode specifies the way in which invalid table warnings should be reported. Different options such as comments, messages or processing instructions are available to report warnings. This can be configured using setWarningReportMode.
Table validation level
The invalid table behaviour depends on the table validation level. The table validation level can either be STRICT or RELAXED. This can be configured using setValidationLevel.
Table processing algorithm version 2
Similar to table processing algorithm version 1, version 2 processes tables defined in the XML input in a special way, considering its structure while keeping the table comparison result valid. This algorithm produces better results in table changes such as table entries overlapping or spanning multiple rows and columns. The changes to such tables are represented at fine grain level rather than duplicating the table row or table itself.
The new approach is based on different techniques:
Comparing the columns of a table first, based on the content that they contain.
Reconstructing a non-ragged table showing column and row adds and deletes but basing the final structure on that of the B input. So we are losing some information about the A structure in order to show changes at a finer granularity. So, for example, where a B span merges what were individual cells in A it will not always be easy to tell which A values came from which columns. A and B values will not however be lost.
Please note that Sequential merge does not support version 2 yet.
Configuration
The version 2 can be enabled using ConcurrentMerge.setTableProcessingAlgorithmVersion2 and has following configurations along with the configurations of version 1 algorithm.
Ignore Column Order
This configuration allows user to ignore the order of the column if they have moved the position between the versions. This can be configured globally for the document using setIgnoreColumnOrder. This global can be overridden by adding a processing instruction within a table. A processing instruction <?dxml-orderless-columns?> can be used to ignore the order of columns on a specific table while <?dxml-ordered-columns?> can be used for ordered column comparison.
Column Keying mode
The configuration parameter ColumnKeyingMode can be used to key the column in different ways such as using the colspec colname or the implicit column position. A processing instruction <?dxml-column-keying-mode auto|colname|position?> can be used within a table element to apply the column keying mode to a specific table.
It may be that you already know which columns from A and B you wish to align. In this case you can give keys to columns so that your pre-determined alignment will override the value based alignment which is the new default. Also, if there are some tables which are better without column keys then you will have to process the inputs to insert the keys where necessary. The user defined column keys can be applied using the processing instruction <?dxml-column-keys "One, Two, Three, Four,"?> within the table element where comma separated list identifies the columns.
Limitations
The Version 2 do not fully support rule configuration. In some cases empty cells will be produced for deleted rows or columns to keep the resolved result valid.
One key weakness of version 2 is that inserted columns do not align even when they are equal.
The Version 2 do not support InvalidTableBehaviour.COMPARE_AS_XML option. This will be added in future release. An exception will be thrown if this setting is used with version 2.
Change representation
The changes to tables are represented differently according to the type of change and table processing algorithm. Following sections highlights few table result to show how different results are produced with different algorithms.
Row span change
ancestor | edit1 | edit2 |
|---|---|---|
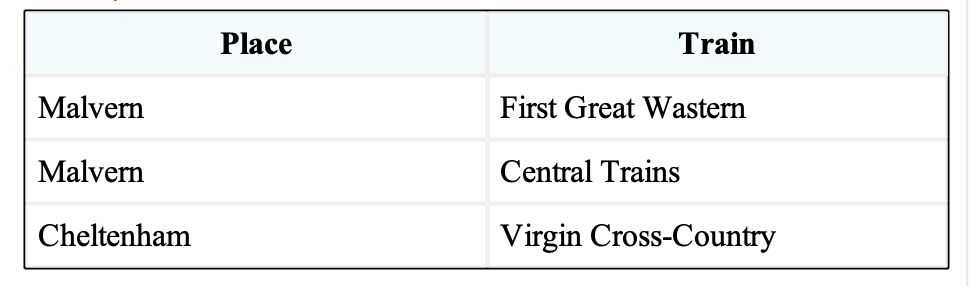 |  |  |
Table processing algorithm version 1 result | Table processing algorithm version 2 result | |
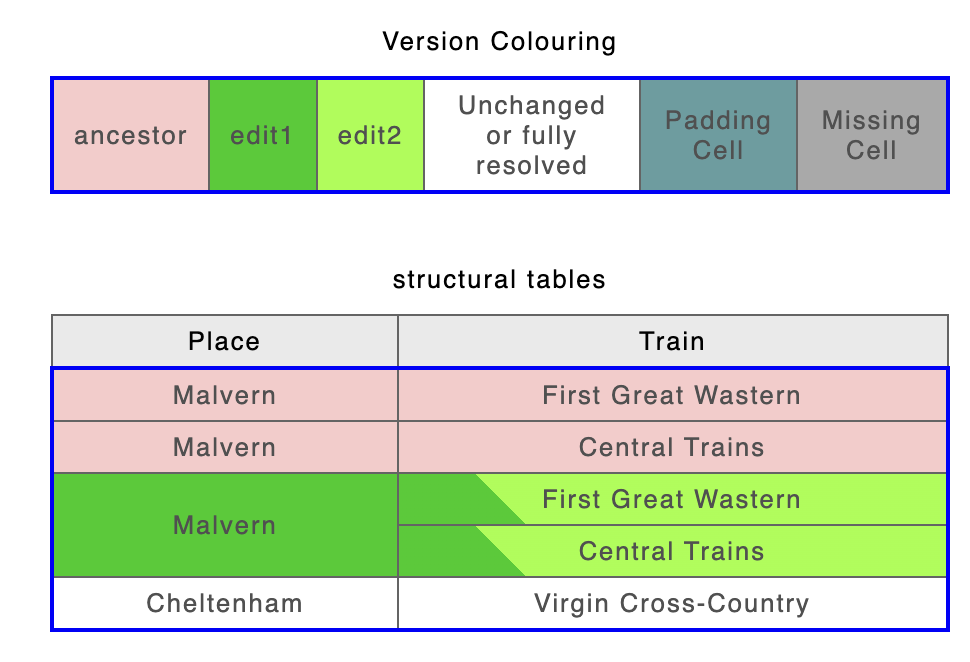 |  | |
Column Span change
ancestor | edit1 | edit2 |
|---|---|---|
 |  |  |
Table processing algorithm version 1 result | Table processing algorithm version 2 result | |
 |  | |
Row and column span change
ancestor | edit1 | edit2 |
|---|---|---|
 |  |  |
Table processing version 1 result | Table processing version 2 result | |
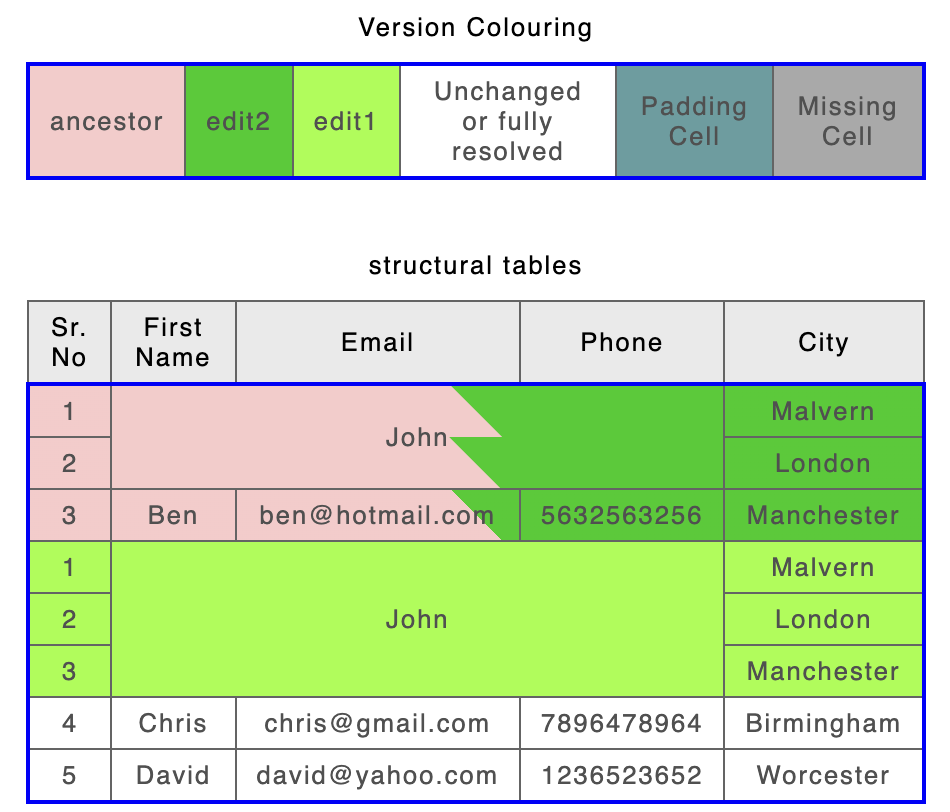 |  | |
Column addition
ancestor | edit1 | edit2 |
|---|---|---|
 | 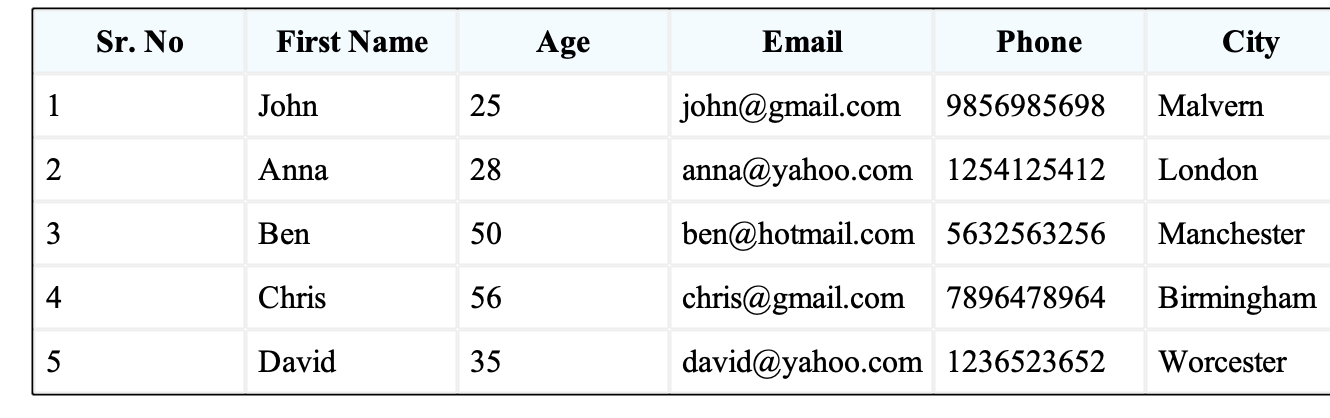 | 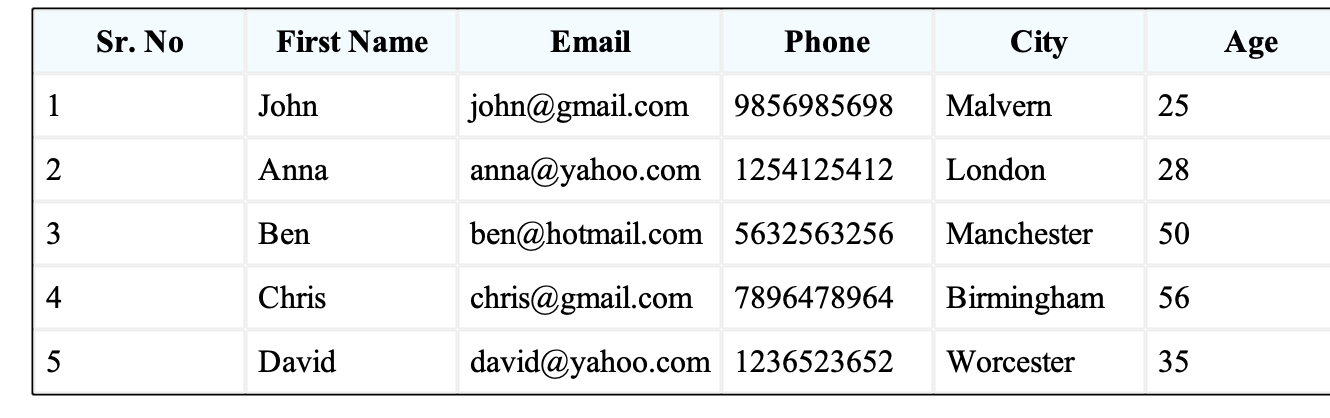 |
Table processing version 1 result | Table processing version 2 result | |
 |  | |
See Comparing Document Tables for a details on how changes are represented along with links to a set of examples table comparisons. Please note that, despite most of the linked table comparisons are two-way comparisons, the same principles apply to three-way or n-way merge operations.