
Concurrent or Sequential Merge?
A user needs to be aware of the way that the documents were edited in order to produce a meaningful DITA Merge result. This page talks about the order of document editing along with different types of merge.
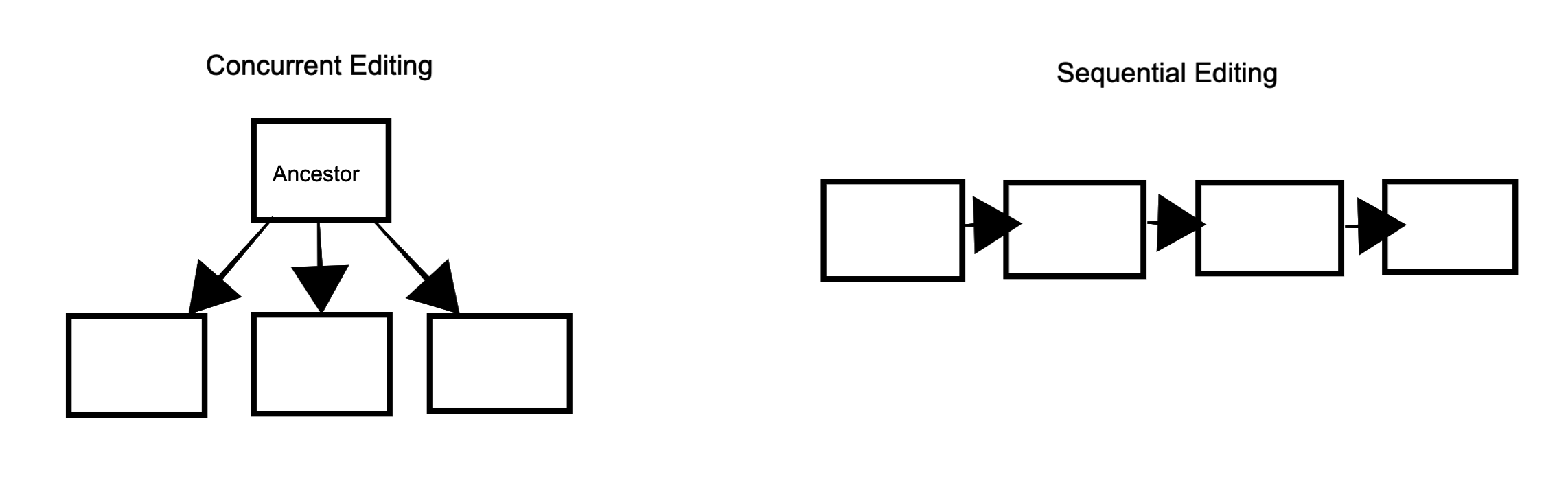
Concurrent Merge
Concurrent merge is used when there are multiple derivatives of a single ancestor.
It recombines multiple DITA files with their common ancestor, analysing their structure and running custom rules to either merge or explicitly mark-up the differences. Its algorithms work through each of the files in turn, examining their structure to match-up all the corresponding elements with the original. The definitions for change categorisation are:
add: Something that does not exist in the ancestor version. The item may be added by one or more of the other versions.
delete: Something that exists in the ancestor version, but is missing in one or more of the other versions.
modify: Something that exists in ancestor and is changed in the versions.
A Three Way Merge is also a concurrent merge. It is frequently used in applications like source code control where two branches have made changes to the ancestor and those branches need to be merged.
Three To Two merge is an extension of a Three Way Merge. The representation of three-way conflicts is not supported by many XML editors. On the other hand, XML editors do support two-way change tracking and this is well understood by users. Therefore, by representing three-way merge conflicts in two-way change tracking, merge provides a significant and useful simplification for users. This is possible without losing important information although some fine detail is lost, but it is much easier for a user to understand the result.
Sequential Merge
Sequential merge is used when a DITA document has been passed around between two or more authors in a sequential manner.
It merges one or more sequentially edited DITA documents. One of the important characteristics of sequential merge is that there is a clearly defined order of editing. The order of editing provides the temporal frame of reference and so the concepts of add and delete are defined relative to the order of editing. This then leads to the following definitions for change categorisation:
add: Something that does not exist in the previous version. When something is added it has never been seen before.
delete: Something that exists in the previous version, but is missing in this version. As soon as something is deleted, then it cannot be added back again, rather if the same item appears again then a new version is created, with no relationship to the deleted item.
modify: Something that exists in one of the version and is changed in the next versions.
Comparisons and Commonalities
Sequential merge takes documents that are derivatives of a previous version whereas concurrent merge takes documents which are derived from an ancestor version.
The root elements of the files must have the same local name and namespace.
For concurrent merge, the version is first aligned with the common ancestor and this alignment will take precedence over alignment between this version and other versions previously loaded into the merge. Whereas in sequential merge, as each successive file is loaded into the merge, the version is aligned with the previous version.
It is possible to generate both concurrent and sequential merge results from any inputs, but one of these is more likely to be the correct choice for a particular set of data. The usefulness of the result will depend on how the DITA inputs have been modified and what type of merge is applied.