
Overlapping Hierarchies in DeltaV2
Introduction
DeltaV2 is the format used to represent the comparison results from two or more input XML documents in a single XML result document. Version 2.1 of this format adds new capabilities for representing types of change associated with overlapping hierarchies. These new capabilities are described here, the full reference for DeltaV2 can be found in the DeltaV2 reference documentation.
This document describes how overlapping markup is annotated using DeltaV2, it describes a method for visualising such markup at a low level and provides a set of sample DeltaV2 fragments that use this visualisation method.
XML Compare V7.0 was the first DeltaXML product to use this format. Its document comparator aligns specially marked elements (e.g. formatting elements) in terms of text content, rather than XML structure. Changes are therefore described in a smarter more granular way, in terms of markup changes such as the addition, removal, shifting or renaming of elements surrounding existing content.
Notes
DeltaXML products supporting the DeltaV2.1 format optimise this format to minimise fragmentation. Some of these samples may therefore not correspond directly to current functionality.
The majority of this document uses 'A' and 'B' as 'version identifiers' that identify document origin, these follow the same convention as used in XML Compare. The DeltaV2 format itself however allows any number of version identifiers (one for each document) which may have any valid name, such as 'ben'.
XML Compare V10.0 introduced a new element called 'deltaxml:contentGroup' for representing the change associated with overlapping hierarchies. The content group format has less text granularity than version 2.1 overlapping hierarchy representation. The last section in this document explains the content group with an example.
Markup Concepts
The DeltaV2 format uses properly nested XML elements to represent two or more overlapping hierarchies with the same text content, the approach used is termed Fragmented markup. Here, one hierarchy is regarded as the primary, but the markup is split each time a 'crossing' element is encountered from another hierarchy. Because DeltaV2 represents changes found in a set of input documents, the primary hierarchy can be considered to be those points where all the hierarchies from the input documents meet.
The approach used here for XML fragmentation is significantly different to existing fragmentation formats for two main reasons: 1) There is always a principal tree comprising elements that are part of the document structure which therefore cannot overlap, and 2) The format must describe differences in content and attributes in addition to differences in markup.
The fragmented markup elements in DeltaV2 use the same names as the elements in the input trees they represent. All elements with start and end points not common to all other input documents have additional DeltaV2 attributes within the DeltaXML namespace (http://www.deltaxml.com/ns/well-formed-delta-v1).
The new attribute names in the DeltaV2 correspond with the fragmented element parts they describe: the whole element (i.e. both start and end tags), the start tag, the middle or the end tag - these are respectively: deltaxml:deltaTag, deltaxml:deltaTagStart, deltaxml:deltaTagMiddle and deltaxml:deltaTagEnd. The value of each of these attributes is one or more comma-separated document identifiers (e.g. 'A') linking the element with a specific input hierarchy.
If an element has to be split in the DeltaV2 format, then the first part will have a deltaTagStart and the second part a deltaTagEnd. If an element is fragmented into three or more parts, then each part between the deltaTagStart and the deltaTagEnd will have a deltaTagMiddle attribute.
DeltaV2 in Practice
In this section we will take a first detailed look at the DeltaV2 format that is the result of a comparison of two input documents with common text content but overlapping hierarchies.
Two input documents
The XML syntax for two input documents A and B is show immediately below, there is one line for each document:
<p>The quick <s>brown fox jumped</s> over the lazy dog.</p>
<p>The quick brown <i>fox jumped over the</i> lazy dog.</p> The input XML trees for this example can be represented diagramatically as:
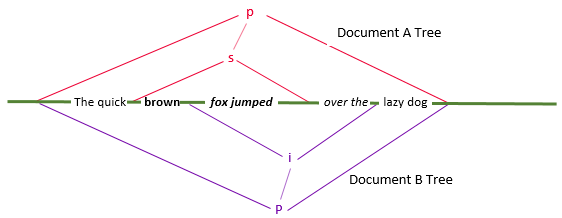
The comparison result
Here is the DeltaV2 format that is the result of the comparison of these two documents:
<p deltaxml:deltaV2="A!=B">The quick
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="A"> brown</s>
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="A">
<i deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="B">fox jumped</i>
</s>
<i deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="B"> over the</i>
lazy dog.
</p>The above DeltaV2 XML shows elements fragmented as described in the Markup Concepts section above, with deltaxml:deltaTagStart and deltaxml:deltaTagEnd showing the extent of the elements in the input hierarchies they represent, with their A and B values indicating the input source. The deltaxml:deltaV2 attributes are standard DeltaV2, simply describing the origin and equality of element text and contents.
Visualising the result
Though the raw DeltaV2 XML may appear complex at first glance, it is designed to be easy to process with standard XML tools. The following HTML visualisation of the XML syntax was produced from this same XML using XSLT, text coloring and underlines show overlaps in the markup in place of the DeltaV2 attributes:
<p>The quick <s> brown </s><s><i>fox jumped</i></s><i> over the</i> lazy dog.</p>The underlines in the processed output of the DeltaV2 (using standard CSS shadows) help with visualising the overlap between the s elements and i elements in the two hierarchies, with the p element common to both. There is however an issue with this rendering: the gray colored tags occur where DeltaV2 XML is fragmented, but they tell us nothing about the hierarchies, they can therefore be removed in the rendering XSLT, as shown below:
<p>The quick <s> brown <i>fox jumped</s> over the</i> lazy dog.</p> Visualising coincident elements
The above rendering of the comparison result is not well-nested XML any more but should make it easier to understand multiple hierarchies. There is however still a problem when visualising elements in multiple hierarchies when the start or end of an element in more than one tree occurs at the same text position.
To handle this difficulty in the samples below, the approach was to repeat tag names (which may be the same) inside each tag for each hierarchy, these are distinguished by their different input-associated colors, with the order of colored tag names chosen to reflect apparent nesting; an example is shown below:
<ss>Same start</s> different finish.</s>The deltaV2 attribute
The deltaxml:deltaV2 attribute is present in all versions of the DeltaV2 format, regardless of the presence, or otherwise, of overlapping hierarchies. It is added first to the root element of the DeltaV2 document and then to each descendant element where the change status of the element cannot be inferred from its nearest ancestor with a deltaxml:deltaV2 attribute.
There is a subtle extension to how this attribute is interpreted in the 2.1 version of this format. The A and B characters in the deltaV2 attribute value identify the document origin of the associated element and any child nodes. Separator characters ('=' or '!=') are used where there is more than one document origin, the separator will only be '=' if attributes, text content, child elements and formatting‑elements are the same.
Samples
This section includes a set of sample DeltaV2 comparison results to illustrate the use of version 2.1 DeltaV2 attributes. While DeltaV2 can express text changes within modified markup from more than two inputs, the samples have been kept relatively simple, so each sample represents just two-way comparisons with the same text content (but different XML structure).
Each sample has two code blocks: the first shows the a document and b document inputs followed by a doc-delta element containing the DeltaV2 format comparison result, the second block shows an HTML visualisation of the DeltaV2 result.
The HTML rendering of overlapping XML in the samples uses the visualisation method explained in the preceding DeltaV2 in Practice section, it was created using a relatively simple visualisation sytlesheet coded in XSLT 2.0.
Removed parent elements
In this sample, the two div wrapper elements present in the A input are missing from the B input.
<sample>
<a>
<div><div><p>The quick brown fox jumped over the lazy dog.</p></div></div>
</a>
<b>
<p>The quick brown fox jumped over the lazy dog.</p>
</b>
<doc-delta>
<div deltaxml:deltaV2="A!=B" deltaxml:deltaTag="A">
<div deltaxml:deltaV2="A!=B" deltaxml:deltaTag="A">
<p deltaxml:deltaV2="A=B">The quick brown fox jumped over the lazy dog.</p>
</div>
</div>
</doc-delta>
</sample><result>
<div><div><p>The quick brown fox jumped over the lazy dog.</p></div></div>
</result>Content split
Here the text in a single p element in the A input, is divided between two p elements in the B input.
To represent the B input in the DeltaV2 format, both p elements have a deltaxml:deltaTag="B" attribute. In contrast, for the A input the first p element has a deltaxml:deltaTagStart="A" attribute, while the second p element has a deltaxml:deltaTagEnd="A" attribute, indicating that the A input spans across both p elements.
<sample>
<a>
<p>The quick brown fox jumped over the lazy dog. To be sure, that was a great idea</p>
</a>
<b>
<p>The quick brown fox jumped over the lazy dog.</p>
<p> To be sure, that was a great idea</p>
</b>
<doc-delta>
<p deltaxml:deltaTagStart="A" deltaxml:deltaTag="B"
deltaxml:deltaV2="A!=B">The quick brown fox jumped over the lazy dog.</p>
<p deltaxml:deltaTagEnd="A" deltaxml:deltaTag="B"
deltaxml:deltaV2="A!=B"> To be sure, that was a great idea</p>
</doc-delta>
</sample><result>
<pp>The quick brown fox jumped over the lazy dog.</p><p> To be sure, that was a great idea</pp>
</result>Content split differently
Here the text in a the A and B inputs, is divided between two p elements, but the split occurs at different points in each input hierarchy.
<sample>
<a>
<p>The quick brown fox jumped over the lazy dog. To be sure,</p>
<p>that was a great idea</p>
</a>
<b>
<p>The quick brown fox jumped over the lazy dog.</p>
<p> To be sure, that was a great idea</p>
</b>
<doc-delta>
<p deltaxml:deltaTagStart="A" deltaxml:deltaTag="B"
deltaxml:deltaV2="A!=B">The quick brown fox jumped over the lazy dog.</p>
<p deltaxml:deltaTagEnd="A" deltaxml:deltaTagStart="B"
deltaxml:deltaV2="A!=B"> To be sure,</p>
<p deltaxml:deltaTagEnd="B" deltaxml:deltaTag="A"
deltaxml:deltaV2="A!=B"> that was a great idea</p>
</doc-delta>
</sample><result>
<pp>The quick brown fox jumped over the lazy dog.</p><p> To be sure,</p>
<p> that was a great idea</pp>
</result>Three elements become two
The text content in input A is divided between three p elements, whilst in B it's divided between two, the split point of B does not coincide with either split point in A.
This is the only example where the deltaxml:deltaTagMiddle attribute is used, this attribute is not absolutely necessary when processing the entire document in document order, but it simplifies processing when the preceding context is not readily available.
<sample>
<a>
<p>The quick brown fox jumped over the lazy dog. To be sure,</p>
<p> that was</p><p> a great idea</p>
</a>
<b>
<p>The quick brown fox jumped over the lazy dog.</p>
<p> To be sure, that was a great idea</p>
</b>
<doc-delta>
<p deltaxml:deltaTagStart="A" deltaxml:deltaTag="B"
deltaxml:deltaV2="A!=B">The quick brown fox jumped over the lazy dog.</p>
<p deltaxml:deltaTagEnd="A" deltaxml:deltaTagStart="B" deltaxml:deltaV2="A!=B">
To be sure,</p>
<p deltaxml:deltaTagMiddle="B" deltaxml:deltaTag="A" deltaxml:deltaV2="A!=B"> that was </p>
<p deltaxml:deltaTagEnd="B" deltaxml:deltaTag="A" deltaxml:deltaV2="A!=B">a great idea</p>
</doc-delta>
</sample><result>
<pp>The quick brown fox jumped over the lazy dog.</p><p> To be sure,</p>
<p> that was </p><p>a great idea</pp>
</result>Classic overlap
This example shows each input hierarchy with a differently named child element that partially overlaps with the other child element.
<sample>
<a>
<p>The quick <s>brown fox jumped</s> over the lazy dog.</p>
</a>
<b>
<p>The quick brown <i>fox jumped over the</i> lazy dog.</p>
</b>
<doc-delta>
<p deltaxml:deltaV2="A!=B">The quick
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="A">
brown</s>
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="A">
<i deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="B">fox jumped</i>
</s>
<i deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="B">
over the</i>
lazy dog.</p>
</doc-delta>
</sample><result>
<p>The quick <s> brown <i>fox jumped</s> over the</i> lazy dog.</p>
</result>Added element in B
Here both inputs have a p element with a common s child element, but input B has a second s child element also.
It's worth noting here that the s element common to both inputs has a deltaxml:deltaV2 attribute value of A=B, elements can only be said to be equal in this way when all child nodes are the same.
<sample>
<a>
<p>The quick <s>brown fox jumped</s> over the lazy dog.</p>
</a>
<b>
<p>The quick <s>brown fox jumped</s> over the <s>lazy</s> dog.</p>
</b>
<doc-delta>
<p deltaxml:deltaV2="A!=B">The quick
<s deltaxml:deltaV2="A=B">
brown fox jumped
</s>
over the
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTag="B">
lazy
</s>
dog.</p>
</doc-delta>
</sample><result>
<p>The quick <s> brown fox jumped </s> over the <s> lazy </s> dog.</p>
</result>Shared element start
Both inputs have a p element with an s child element starting at the same point, but the child element in B ends after that in A.
<sample>
<a>
<p>The quick <s>brown fox jumped</s> over the lazy dog.</p>
</a>
<b>
<p>The quick <s>brown fox jumped over the lazy</s> dog.</p>
</b>
<doc-delta>
<p deltaxml:deltaV2="A!=B">The quick
<s deltaxml:deltaTagStart="B" deltaxml:deltaTag="A" deltaxml:deltaV2="A!=B">
brown fox jumped
</s>
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="B">
over the lazy
</s>
dog.</p>
</doc-delta>
</sample><result>
<p>The quick <ss> brown fox jumped </s> over the lazy </s> dog.</p>
</result>Shared element end
Both inputs have a p element with an s child element ending at the same point, but the child element in B starts after that in A.
<sample>
<a>
<p>The quick <s>brown fox jumped over the lazy</s> dog.</p>
</a>
<b>
<p>The quick brown fox jumped over the <s>lazy</s> dog.</p>
</b>
<doc-delta>
<p deltaxml:deltaV2="A!=B">The quick
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="A">
brown fox jumped over the</s>
<s deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="A" deltaxml:deltaTag="B">
lazy
</s>
dog.</p>
</doc-delta>
</sample><result>
<p>The quick <s> brown fox jumped over the <s> lazy </ss> dog.</p>
</result>Visualising with ContentGroup
The contentGroup element contains two types of child elements; text and content elements. The text elements show only the text changes, ignoring any formatting, so that users who wish to concentrate on only textual changes need only examine these. The content elements show both text and formatting changes grouped together in a way that makes it easier to see all the changes.
<document deltaxml:deltaV2="A!=B!=C!=D">
<para deltaxml:deltaV2="A!=B!=C!=D">This paragraph will have
<deltaxml:contentGroup deltaxml:wordDelta="A=B!=C=D" deltaxml:deltaV2="A!=B!=C!=D">
<deltaxml:text deltaxml:deltaV2="A=B">words in bold</deltaxml:text>
<deltaxml:text deltaxml:deltaV2="C=D">words in italics</deltaxml:text>
<deltaxml:content deltaxml:deltaV2="A">words in bold</deltaxml:content>
<deltaxml:content deltaxml:deltaV2="B"><bold>words in bold</bold></deltaxml:content>
<deltaxml:content deltaxml:deltaV2="C">words in <italic>italics</italic></deltaxml:content>
<deltaxml:content deltaxml:deltaV2="D"><underline>words in <italic>italics</italic></underline></deltaxml:content>
</deltaxml:contentGroup> in
<deltaxml:textGroup deltaxml:deltaV2="A=B!=C=D">
<deltaxml:text deltaxml:deltaV2="A=B">the following</deltaxml:text>
<deltaxml:text deltaxml:deltaV2="C=D">this</deltaxml:text>
</deltaxml:textGroup> version.
</para>
</document>One intended use case for the content group formatting element output format is for Graphical User Interface (GUI) systems which can allow the end user to choose which type of differences to show; either just text or text and format. The following example illustrates one way this might be shown. The default display is to show only text additions and deletions, and when the highlighted text block is selected, a dropdown could show both the formatting and text changes from each version.
