
User Guide
Introduction
DeltaXML DocBook Compare highlights changes between two DocBook files. It performs a detailed comparison between the two files and automatically adds revision flags to highlight added, deleted or changed text. Alternatively, DocBook Compare can be configured to output the differences in some XML editor specific 'track change' formats, as discussed in the section called output-format.
You do not need to 'track changes' and you can compare any versions of your document, for example minor changes between editing sessions or changes between customer releases.
Use DeltaXML DocBook Compare for quality control, or to provide your customers with details of the updates you have made so that it is easier for them to understand changes in your new version.
You can show the changes in any colour or text decoration by modifying your publishing pipeline. Whether you are publishing to the web or printed page, you can highlight changes with DeltaXML DocBook Compare.
Output Formats
The DeltaXML DocBook Compare product can represent the differences between two inputs using a variety of output formats. Each output format has its own limitations on what types of change are supported and where changes are allowed to take place. For example, DocBook's own change markup language does not support changes in attributes.
The DeltaXML DocBook Compare product currently provides the following output formats:
DocBook Markup. This output format marks differences using DocBook's own change markup scheme.
Arbortext Tracked Changes. This output format marks differences using the Arbortext Change Tracking Markup Specification. See the PTC Arbortext website.
FrameMaker Tracked Changes. This output format marks differences using the FrameMaker Tracked Changes format, which is supported by the Adobe FrameMaker Editor.
oXygen Tracked Changes. This output format marks differences using the oXygen Tracked Changes format, which is supported by the oXygen Editor and Author products.
XMetaL Tracked Changes. This output format marks differences using the XMetaL Tracked Changes format, which is supported by the XMetaL Editor.
The 'default' output format is 'DocBook Markup', which identifies change using DocBook's own change markup scheme as discussed in the section called “DocBook Markup” below.
The remaining output formats represent the differences between two inputs using tracked change formats. Here, the intention is to enable the differences to be viewed, accepted, and rejected in an editor or word-processor that supports the given tracked changes format.
The remainder of this section discusses the output formats in more detail.
DocBook Markup
When using DocBook Markup the output of a comparison is itself a DocBook document. The DocBook Markup output format uses the revisionflag attribute to identify change. This attribute can be added to any DocBook element, taking one of the following values: changed, added, deleted, off. These values can be used to highlight changes between two given versions of a document.
The revisionflag values are used on elements as follows:
when an element existed in the original document but is no longer present, a
revisionflag="deleted"attribute is added to that element,when an element exists in the new version of the document but was not present in the original a
revisionflag="added" attribute is added to that element,for certain elements, attribute changes cause a
revisionflag="changed"attribute to be added to the element
In DocBook 4.x, revisionflag attributes are not allowed on certain elements. Changes to these elements therefore cannot be displayed.
Changes to text content are handled slightly differently. Since it is not possible to add attributes to text, it must first be wrapped in an element that can have the attribute added. The <phrase> element is intended for this kind of purpose.
Text that was in the original document but is no longer present is wrapped with <phrase revisionflag="deleted">...</phrase>, text that is only included in the new version of the document is wrapped with <phrase revisionflag="added">...</phrase>.
If text changes are made in a context where <phrase> is not a valid element, there is the option to use textual markers to display the change. This option is controlled using the show-non-phrase-changes parameter, which is set to true by default. Text changes are marked up as follows:
text that existed in the original document but is no longer present is wrapped like this:
-[[...]]-text that exists in the new version of the document but was not present in the original is wrapped like this:
+[[...]]+As well as marking the text in this fashion, the element that contains the text will also have a
revisionflag="changed"attribute added to it
If the show-non-phrase-changes parameter is set to false, then only the text from the new version of the document will be output, without any marking.
Arbortext Tracked Changes
When using Arbortext Tracked Changes Markup the output of the comparison is an Arbortext tracked change version of a DocBook document. Here DocBook elements can contain Arbortext tracked change elements, and vice versa. One consequence of this approach is that the resulting tracked change document does not conform to the DocBook specification. In order to return an Arbortext tracked change document back to the DocBook specification all changes need to be accepted or rejected (and the tracked change author information has to be removed).
Assuming that the inputs to the comparison are valid DocBook documents and all the changes to the output are accepted (or rejected) as previously discussed, then the resulting document will be a valid DocBook document. Note that in general it is not possible to guarantee that an arbitrary combination of 'accepted' and 'rejected' changes will result in a valid document, due to the granularity of change.
The generated tracked changes use three of the available tracked change elements:
atict:add. For inserted content;
atict:del. For deleted content;
atict:chgm. For attribute modification (outside the context of a table).
Changes within comments and CDATA Sections results in the whole of the old version of the text being marked as deleted, and the whole of the new version of the text being marked as inserted.
The Arbortext tracked change format does not support changes to processing instructions or those comments that are outside the body of the DocBook document. It does, however, support both cell and row level changes within tables.
FrameMaker Tracked Changes
The FrameMaker Tracked Changes Markup output format is a valid Docbook document that includes annotations to represent changes in the document.
This format employs FrameMaker's method for tracking changes, exploiting XML processing-instructions and comments to mark additions and deletions within documents.
The FrameMaker tracked change format is restricted to the Author and WYSIWYG views, these views do not support edits within XML marked as CDATA, changes to CDATA sections are therefore converted to normally parsed XML content. This format uses a pseudo-entity '&fm-double-hyphen;' to allow two adjacent hyphen characters to be represented within comments - which the track change format uses to contain deleted content.
As with most editors, FrameMaker has a few limitations on what types of change can be tracked for different element types, an example is the addition/deletion of table rows. For this specific example, the output format defaults to showing changes as changes in the text content of the row cells. This is affected by the parameter setting for framemaker-tcs-table-change-mode. However, other limitations have not been fully explored and its possible that some changes marked in the output format will be ignored by FrameMaker.
oXygen Tracked Changes
When using oXygen Tracked Changes Markup the output of the comparison is itself a DocBook document. This output format uses processing instructions to identify change, where deleted content is typically contained within the processing instruction and inserted content is typically sandwiched between two processing instructions, one marking the start of the insertion and the other the end. Hence, removing (or ignoring) the processing instructions has the affect of accepting all changes to the document.
Comments and CDATA Sections are handled specially, as processing instructions cannot be placed inside their content. Instead, changes are identified by a sequence of processing instructions that immediately follow the Comment or CDATA Section, which mark the location of the change by using a character counting technique. Here, deleted content is contained in the processing instructions, whereas inserted content is already in the Comment or CDATA Section text itself. This preserves the principle of being able to accept all the changes within a document by either ignoring or removing the tracked change processing instructions.
Similarly with attributes changes are identified by a sequence of processing instructions that immediately precede the element containing the changed attribute.
The oXygen tracked change format does not support changes to processing instructions, or those comments that are outside the body of the DocBook document. It does, however, support both cell and row level changes within tables.
XMetaL Tracked Changes
When using XMetaL Tracked Changes Markup the output of the comparison is itself a DocBook document. This output format uses processing instructions to identify change in a similar manner to that of oXygen tracked change format. However, it does not support changes to attributes, comments, changes within CDATA sections, or row or cell level table changes.
Changes within CDATA Sections are handled by moving the change to the CDATA Section level as a whole. Therefore any textual change with in a CDATA section results in the old version of the whole CDATA section being marked as deleted, and the whole of the new version of the CDATA Section being marked as inserted.
There is a special XMetaL specific parameter (xmetal-tcs-table-change-mode) which controls what happens when row or cell level table changes are present. These changes can be pushed down to the cell content level, where the content of each cell within the changed region is appropriately deleted and inserted; this is the 'default' behaviour. The second option is that changes to rows or cells can be pushed up to the table level, so that the old and new versions of the table as a whole are tracked. The third option is that changes can simply be ignored (which mirrors what the XMetaL editor would do). However, selecting the ignore mode means that all changes within a table are ignored, not just those that are at the 'row' or 'cell' level. This is deliberate, as we believe that partial tracking of changes within a table would be confusing.
How is the Comparison Performed?
DeltaXML DocBook Compare makes use of the fact that DocBook is an XML format when performing document comparison. XML documents are machine readable documents that conform to a set of rules defined by the W3C. For more information on XML see XML Resources.
The document comparison is performed by another of our products, XML Compare, with various pre-configured pre- and post-processing steps, referred to as a filter pipeline.
XML Compare works by matching together elements that have the same name and, where possible, the same or similar contents. This means that a paragraph (<para> element) can only ever be compared against another paragraph and will never be compared against a simple paragraph (<simpara> element). Understanding this is a key part of understanding how the comparison works.
When deciding which elements match best, e.g. which amongst a number of possible paragraph pairings is the best match, XML Compare uses the words within an element. Elements that have the same or similar content are much more likely to be matched together than those that are quite different. Once this matching phase has taken place, XML Compare will then compare the contents of the two elements it has matched, recursing in this fashion until it reaches the bottom of the XML structure.
Controlling Matching
It is possible to influence the way in which the element matching takes place using 'keys'. When an element has a key assigned to it, it will only ever match an element in the other document that has the same key assigned to it (as long as it also has the same element name, this principle never changes). Key matching takes precedence over content matching and so elements with the same key will match even if their content is very different. The simplest way of adding keys to an element is to use the DocBook id (or xml:id in DocBook 5) attribute. With the correct setting for the keying-mode parameter selected (in this case use 'useId'), this is then converted into a key (the deltaxml:key attribute) as part of the pre-processing performed by DocBook Compare and used by XML Compare to match elements together. Please note that an element with a key will never match an element without one.
One potential problem with using ids as keys is that ids are also used for cross referencing. The following scenario highlights the potential problem: two paragraphs exist in the original version of the document, neither having an id. In the second version of the document, the content of the first paragraph remains the same but the second paragraph now includes a cross-reference to the first paragraph. This means that the first paragraph now requires an id so that it can be referenced. If ids are used as keys, the first paragraph will not match correctly across the two documents (it doesn't have a key in the first document and does in the second, therefore it will not match). This leads to an undesirable result. One way to avoid this situation is to always add ids to elements, even if they are not being cross-referenced. Another solution is to use a different keying mode that does not use an element's id value as a key.
There are other ways to add keys to the document. One is to use the deltaxml:key attribute directly on the elements that you wish to key. While this will aid in matching, the deltaxml:key attribute is not a valid DocBook attribute and so you must either customise the DocBook DTD (or RNG grammar) to allow it, or switch off input validation when you run DocBook Compare. This attribute will be used for keying without having to configure the keying-mode parameter. The default setting makes use of any existing deltaxml:key attributes.
Another way of adding keys is to use the condition attribute available on most elements. If you choose this method, the keying-mode parameter should be set to useCondition.
For more information on keying, see Using Keys with Ordered Data. For more information of the keying-mode parameter, see keying-mode.
Pre-processing
As well as converting id or condition attributes to keys, the pre-processing stages perform many other tasks in the documents. These tasks are described below, along with any parameter settings available for configuring them.
Removing revisionflags
Because the result uses revisionflag attributes to display the changes between the inputs, each of the inputs must first have any existing revisionflag attributes removed. This avoids confusion between pre-existing attributes and those added as part of the comparison.
Preserving comments and processing instructions
XML comments (text contained in <!-- --> markup) and processing instructions (special instructions marked as <?instruction_name more details ?>) in the document need to be converted into other XML markup in order to be output in the result document. This task is carried out before comparison, the elements are then compared and they are converted back into comments and processing instructions afterwards.
Whitespace preservation
For most DocBook elements, whitespace is not significant (e.g. multiple spaces and newlines are effectively turned into a single space when converting to a published format such as PDF). Therefore, when using the DocBook markup such spaces are 'normalized' before comparison.
Tracked changes output formats are intended for use with editors, where 'roundtrip' processing is the typical behaviour. In this case we are typically not interested in whitespace change, but want to preserve the document indentation. Therefore, we 'ignore' changes in whitespace.
The whitespace-processing-mode parameter provides a means for configuring how whitespace differences are to be handled.
Formatted elements
For some elements, whitespace is important and should never be normalised, regardless of the setting of preserve-whitespace. programlisting, literallayout and address are examples of elements where whitespace has meaning and is usually used in the final published document. These elements have the xml:space="preserve" attribute added to them which prevents any whitespace normalisation.
Word by word
When comparing text, the comparison can treat text blocks as a single chunk of text and compare one chunk against another or it can treat it as a sequence of words, comparing one word against another. The word-based comparison gives more understandable results at a much finer-grained level and is the default setting. If you wish to turn it off, set the word-by-word parameter to false. See word-by-word for more details.
Table processing
Table comparison is a complicated matter and part of the requirements for processing DocBook tables is that the table is a valid 'CALS Table'. This is a separate standard that defines how tables should be constructed and is used as the definition for DocBook tables. However, it is possible for a table to be valid according to the DocBook language but semantically invalid according to the CALS table specification. Part of the input processing analyzes tables in the document, performs normalization and annotates them to inform later processing stages about their validity.
Table normalization involves the following:
Converting a column width (the
colwidthattribute) value of*to1*. These are semantically equivalent but would register as a difference when compared.Explicitly outputting inferred column specifications (
colspecelements). For example, if the first column defined is listed as column 2, then there is an inferred default entry for column 1. The input processing adds an explicit definition of such inferredcolspecs.
DocBook Compare also includes support for comparing HTML tables. Processing for HTML tables is slightly different as they are a much simpler form of table than CALS tables.
See Tables for more details on how tables are compared.
Post-processing
Following the comparison several post processing tasks are applied. Some of these tasks appropriately remove additional markup that was added by the input processing stages, such as removing the word-level element wrapping. Other tasks include identifying conflicting change in element's id, and marking up the output as specified by the output-format parameter.
The remainder of this section presents some of these output processing tasks in more detail.
Conflicting [xml:]id processing
DocBook can use XML id attributes as the target (or anchor points) for cross-referencing. The comparison of the documents can identify when such ids have been modified, deleted, or inserted. In principal, id modification can be handled by keeping the newer version of the id, and ensuring that all the references to the old version of the identifier are replaced by the new version of the id. However, it is possible that the new version of the identifier existed in a deleted portion of the original document. In this case, the deleted id and any reference to it needs to be renamed.
Note that it is not possible for the new version of a 'valid' DocBook document to have two (or more) elements with the same XML id, therefore any conflict in id name must be in the deleted portion of the document (at least for a two way comparison).
Currently any element that contains a linkend, endterm, otherterm or startref attribute is considered to be the source of a cross-reference to an [xml:]id with the same value as that of the source attribute. Only these attributes will have their values updated by the conflict id processing (in addition to the ids themselves).
Attribute change
Attribute changes are detected by the comparison process and handled by the post-processing filters as discussed in the sections Output Format and Attribute Change. However, there is one general exception to this handling, in that any XML id attribute changes that are updated by the conflict id processing (the section above called “Conflicting [xml:]id processing”) may have had their values resolved. In such cases, there is no attribute change to report by the subsequent attribute change processing.
DocBook 5 and Entities
Since DocBook 5, the grammar has been specified using RELAX NG (RNG) rather than DTD (as it was in DocBook 4.x). Although DocBook 5 does have a DTD version of the grammar, most editors use the RNG grammar for validation.
An editor may use the xml-model processing instruction for validation purposes, e.g.
<?xml-model href="http://www.oasis-open.org/docbook/xml/5.0/rng/docbook.rng" schematypens="http://relaxng.org/ns/structure/1.0"?>See [xml-model] for more details.
If a document that does not use a DTD grammar needs to include the use of entities, these may be defined in the DOCTYPE of the document. The following example shows how to define an entity to use as the title of book:
<!DOCTYPE book [
<!ENTITY cp_title "This is the Book Title">
]>
<book xmlns="http://docbook.org/ns/docbook" version="5.0">
<title>&cp_title;</title>
...
</book>If an editor is using the xml-model processing instruction for validation, it will usually ignore this DOCTYPE when validating and use it only for the declaration of entities. However, the XML parser used in DocBook Compare will attempt to validate the document based on this DOCTYPE and, as there is no reference to a definition of the root element (either in an external file or internally in the DOCTYPE), the validation will fail and DocBook Compare will terminate.
There are a couple of ways to work around this issue:
Turn off input validation on DocBook Compare. See validate-inputs for more details on this.
Supply a complete DTD that will be validated correctly e.g.:
<!DOCTYPE book PUBLIC "-//OASIS//DTD DocBook XML 5.0//EN" "file:///usr/local/java/docbook-5.0/dtd/docbook.dtd" [
<!ENTITY cp_title "This is the Book Title">
]>
<book xmlns="http://docbook.org/ns/docbook" version="5.0">
<title>&cp_title;</title>
...
</book>Please see the the section called “Lexical Preservation: Preserving Entities, DTDs, CDATA, PIs and Comments” section for a discussion of how entity declarations and references are handled.
Product Features
The DeltaXML DocBook Compare product has several special features for handling specific situations. This section focuses on tables, round-trip processing (via lexical preservation), and attribute change.
Tables
DocBook tables (which use the CALS table model) are handled slightly differently from the rest of the document because displaying change, particularly structural change, in tables is more difficult. For this reason, structural table changes are shown at various different levels of granularity. Our main aim in the table processing is to produce a result where the changes can be seen in as much detail as possible but with the result document still maintaining validity against the DocBook specification and the CALS table specification. Producing an invalid result document can cause problems further down the publishing pipeline, particularly during FO to PDF processing.
Simple Structural Change
When the column definitions for the two tables have not changed, it is possible to represent changes to column or row spanning at the effected row granularity. Rather than repeating the whole of the table in two tgroup elements, it is possible to repeat only individual rows, or in some cases a set of consecutive rows from the original document (marked with revisionflag="deleted") followed by rows from the latest document (marked with revisionflag="added"). The number of rows that are repeated depends on what type of structural change has occurred. If the change involves changes to column spanning within a single row that does not overlap other rows and is itself not overlapped, it is possible to repeat only that single row. If column spanning changes occur on a row that overlaps other rows or is itself overlapped, it is necessary to group together all of the rows affected by the row spanning and repeat them together. This is also the case for any changes involving changes to row spanning.
Complex Structural Change
Some structural changes are too complex to represent in a single result table section (the tgroup element) and so the result document contains a table with two table sections: the first contains the table from the original document with a revisionflag="deleted" attribute on it, the second contains the table from the latest document with a revisionflag="added" attribute on it. Although it is not possible to see individual changes to rows/cells etc that occurred between the document versions, it is possible to see the two table versions and, provided that the inputs were both valid, be sure that the result document is valid.
This type of result is produced when a table contains changes to row or column spanning and at the same time changes to the column definitions (e.g. changed column names or added/deleted columns).
Other Changes
Other kinds of simple structural change can be represented within a single table without needing to repeat any rows. For example, column deletion in a table that does not have any changes to column or row spanning can be represented by marking each of the deleted cells with the revisionflag="deleted" attribute.
Orderless Tables
Sometimes the order of rows within a table is insignificant. For example, consider a simple product information table, where the first column of the table contains a unique product name, the second column its 'tag line', the third column its standard price, etc. The rows in this table can be reasonably ordered in a variety of ways, such as by 'name', or by 'price'. When two versions of a document are compared that use different row ordering mechanisms, a significant number of rows are likely to be added and deleted due to them moving position. If such differences are insignificant then an orderless row comparison would be useful.
Orderless row comparison support can be provided so long as there is no row spanning within the tables being compared. In such cases, the <?dxml-orderless-rows?> processing instruction can be added within the element that directly contains the rows that are to be processed in an orderless fashion. It is important to ensure that this processing instruction is added to the relevant table in both input documents.
The orderless comparison algorithm is greatly improved through the use of unique row keys. Adding a <?dxml-key id1?> processing instruction within the row element, sets that rows key to 'id1'. It is also possible to specify the row 'cell position' that is used for defining the default value for a row's key. For example, the <?dxml-orderless-rows cell-pos:2?> processing instruction, specified on the element directly containing the row elements, specifies that the text content of the row's second cell (e.g. <entry> or <td> element) should be used as the row's key. Note that the row cell position takes no account of 'column' data (e.g. @colnum attribute), it just counts the number of cells.
Ordered Tables
Even though the default comparison behaviour of rows within tables is to treat them as ordered, there are times when one might want to specify an ordering informed by a knowledge of the structure of the particular table. For example, when rows are either added or deleted it is often useful to specify an ordering to force the comparison result to align using a specified row cell as a key. DocBook Compare provides a method for achieving this called ordered table auto-keying. This feature uses a processing instruction mechanism similar to that used with Orderless Tables as described above.
Ordered row auto-keying is enabled by adding a <?dxml-ordered-rows?> processing instruction within an element that directly contains the rows to be processed in an ordered way. This processing instruction must be added to the desired table in both of the input documents.
Two methods are provided in order to specify the keying: explicit row keys and cell position.
To explicitly add a key to a table row, you must add a <?dxml-key id?> processing instruction within the row element to be keyed. The id can be any unique text such as an element name, or a unique generated number. It is important to ensure that each key specified is unique within a table. For example, adding a <?dxml-key id1234?> processing instruction within the row element sets that row's key to 'id1234'.
It is also possible to specify the row 'cell position' that is used for defining the default value for a row's key. For example, the <?dxml-ordered-rows cell-pos:2?> processing instruction specifies that the text content of the row's second cell (e.g. <entry> or <td> element) should be used as the row's key. Note that the row cell position takes no account of 'column' data (e.g. @colnum attribute), it just counts the number of cells.
Lexical Preservation: Preserving Entities, DTDs, CDATA, PIs and Comments
The DeltaXML DocBook Compare product provides a selection of output formats with different intended use cases as discussed in the section called “Output Formats”. Some are intended for use in a publication pipeline, whereas others are intended for onward review and editing (we refer to this as 'round trip' processing). For onward editing, it is useful to provide the user with a document that is as close to the original input documents as possible. For example, it is important not to expand entity references and CDATA sections.
These lexical preservation modes can be set by the 'preservation-mode' parameter as discussed in the Parameters Appendix. The remainder of this section provides: an overview of each lexical preservation mode (the section called “Modes” below); a detailed account of precisely what is preserved in each mode (the section called “Details” below); and a discussion on the limitations of preservation (the section called “Limitations”);
Modes
Round trip preservation mode.
When using a track-change output format, a user is likely to expect that accepting all the changes would result in the 'B' document, whereas rejecting all the changes would result in the 'A' document. The 'round trip' preservation mode is designed to achieve this as far as possible, within the limitations of standard XML parsing and XSLT 2.0 transformation technologies. However, as some data cannot be tracked using tracked change markup, it is necessary to choose either the 'A' or 'B' version of that data. By default the result document uses data in the 'B' document in preference to that in the 'A' document. Hence, accepting all changes is likely to be close to the 'B' document whereas rejecting all changes may not be as close to the 'A' document.
Document preservation mode.
When marking changes using attributes, such as revision flags, the user is likely to expect full content expansion. Here entity references and CDATA sections are expanded and compared, rather than kept in their original source form. This typically enables finer grained change identification and display. It can also significantly improve the aligning of the documents before the comparison is performed. This type of processing is performed when using the 'document' preservation mode.
Document and attribute preservation mode.
One issue with the document preservation mode is that all the attributes that are provided by the DTD are retained in the output, which can lead to unnecessary clutter in the output, which both increases the size and decreases its clarity for manual review/editing. The 'document and attribute' preservation mode address this issue by tracking which attributes have been supplied by the DTD, and removing them so long as they have not changed.
Entity reference and nested entity reference preservation modes.
These are variations on the 'round trip' mode to enable expert users to know when the underpinning definitions of an entity have changed, as explained in the next section called “Details”.
Details
The table below shows the different preservation modes and their effect on how various items in the file are preserved.
Table 1. Preservation Modes
Preservation Mode | Preserve Comments & Processing Instructions | Preserve XML Declaration & Doctype | Preserve defaulted attributes | Preserve CDATA sections & whitespace | Preserve entity references | Preserve entity references & content | Preserve nested entity references & content |
|---|---|---|---|---|---|---|---|
document | on | on | off | off | off | n/a | n/a |
docAndAttrib | on | on | on | off | off | n/a | n/a |
roundTrip | on | on | on | on | on | off | off |
entityRef | on | on | on | on | on | on | off |
nestedEntityRef | on | on | on | on | on | on | on |
The effects of turning these preservation items 'on' or 'off' is now discussed in the following list, where the use of 'this column' in an item's description refers to the corresponding column in the above table.
Preserve Comments & Processing Instructions.Comments and Processing Instructions (PIs) in the 'B' document are preserved in the result, whereas comments and PIs in the 'A' document (that are not also in the 'B' document) do not appear in the result. The exception here is that PIs that represent oXygen tracked changes are removed prior to comparison so that they do not get confused with the changes identified by the comparator. Further, neither comments or PIs in the internal DTD subset are currently preserved.Preserve XML Declaration & Document Type (DTD & internal subset).Most of the XML declaration, doctype and internal subset data is preserved (for the preservation modes that contain an 'on' in this column). A current limitation is that comments and processing instructions within an internal subset are lost. Another limitation is that XML declaration's standalone marking is not preserved.Preserve defaulted attributes.Default attribute values can be specified in a DTD and these are automatically put onto the elements in the document by the parser. If they are preserved as defaulted attributes (i.e. an 'on' in this column), then these default values will not appear in the result document.Preserve CDATA sections and whitespace.CDATA (character data) sections are preserved in the result (for the preservation modes that contain an 'on' in this column). Insignificant whitespace characters are treated as normal whitespace characters, and modifications in whitespace are by default ignored in the output.Preserve entity references.General parsed entities are preserved as entities - rather than expanded (i.e. replaced by their content) - in the result document when an 'on' is in this column. This is usually what you want when you continue to edit the document. For example, consider two documents that differ in how the name of a city - London - is represented: in the first document the city is written as the string 'London', and in the second document the city is written as an entity reference '&city;' whose value is the string 'London'. In this case, modes with an 'on' in this column the two representations of city London are marked as different, because the unexpanded entity is different from the text, whereas those modes with an 'off' in this column mark the two representations of the city London as the same, because the expanded entity reference is the same as the text.Preserve entity references and content.This is intended only for expert users who understand how entities work. InroundTripmode you will not see changes in entity references in the (unusual) situation where the definition of these entities is different in the two documents. For example, consider two documents containing the entity reference '&city;' that differ only in the value of the 'city' entity, which has changed from 'London' in one document to 'Birmingham' in the other. Both of these documents use the same '&city;' entity reference, which would be marked as unmodified as it is identical from the round trip (source document) perspective. If you need to see such changes, then use a mode with an 'on' in this column. In the result document, there can only be one entity definition and this will be either from the original ('A' document) or new ('B' document). Therefore the entities are guaranteed to be the same in the result document, and so any difference is shown by adding and removing an identical element.Preserve nested entity references and content.This is intended only for expert users who understand the way one entity can reference another. An 'on' in this column means that subtle changes in entity reference structure are shown. The full structure of nested entities is preserved and compared and any changes are shown. This is useful in some complex cases where the overall semantics of an entity does not change, but the way in which it is defined changes. For example, consider a document that contains a reference to the entity '<!ENTITY ent "&inner1;">', where the 'inner1' entity has the value 'val'. Let a second version of the document be the same as the first, except that the inner entity reference is renamed to '&inner2;'. In this case, both the syntactic and semantic analyses will miss this change, as the syntax analysis compares '&ent;' against itself and the semantic analysis compare the text 'val' against itself. An 'on' in this column means the comparator will detect such changes in the internal definition of an entity, and marks them using the same scheme as above: the addition and deletion of an identical entity reference.
Limitations
There are some fundamental limitations on what changes can be shown, which reflect the nature of a given output format and XML parsing and processing technology. These fundamental limitations include:
Many output formats - such as oXygen and XMetaL tracked change formats - cannot represent changes in attributes. In these cases, it is possible to configure the resultant document to contain the 'A' version, the 'B' version, the 'A' version if it exists otherwise the 'B' version, etc; see the 'modified-attribute-mode' parameter documentation for details.
Many output formats - such as DocBook markup and Arbortext tracked change formats - cannot represent changes in the document type and internal subset data. In these cases, it is possible to configure the resultant document to contain the 'A' version, the 'B' version, the 'A' version if it exists otherwise the 'B' version, etc; see the 'unmarked-change-mode' parameter documentation for details.
Some changes in white space cannot be reproduced, as whitespace outside the root element of a document is not reported by an XML parser.
Attribute Change
Attributes are often used to provide styling hints or instructions to an output processor, such as the colour of the text, its size and alignment, etc. Such change presentation, though important, does not typically change the meaning of the document. Therefore, the default mode of behaviour is to keep the attributes of the latest (or 'B' document), and ignore the attributes of the 'A' document.
Attributes can also be used to contain semantic information, such as: links to files, web sites, bookmarks and email addresses; identifiers for bookmarks; and tokens for conditional processing. Here, a user might reasonably want to know about changes to these cross-references and conditional processing. The modified-attribute-mode parameter provides a facility to either control which attributes to use in the output, or whether to augment the output with attribute change data.
When the modified-attribute-mode parameter is set to encode-as-attributes the resulting file contains the 'B' version of the attributes, along with a new attribute that describes how this differs from the 'A' document, in this format:
ac:genName="ctId,changeType,atName,origVal"
where ac identifies the http://www.deltaxml.com/ns/attribute-change namespace and:
genName - is the generated attribute name that is unique to the containing element, but otherwise unimportant;
ctId - is the change transaction id (and will be the same for all changes made during the comparison);
changeType - is the type of change (one of - insert, remove or modify);
atName - is the name of the changed attribute (in the 'prefix:name' format);
origVal - is the original 'A' version of the attribute.
Such an attribute value can be split into the ctId, changeType, atName, and origVal fields by performing a left to right tokenisation where ',' is the token separator. Note that care must be taken to ensure that a maximum of four tokens can be generated, as the original value field may itself contain commas.
Encode-as-attributes example.
Input A
<graphic catalog-id="EG01144B" width="220pt" />Input B:
<graphic catalog-id="BC_EG01144B" tofit="1" />Output with modified-attribute-mode=encode-as-attributes
<graphic catalog-id="BC_EG01144B" tofit="1"
ac:attr122445="D1E1,modify,catalog-id,EG01144B"
ac:attr132423="D1E1,remove,width,220pt"
ac:attr134234="D1E1,insert,tofit" />Images
Docbook images may be defined using imagedata elements, using fileref attributes to point to external image files. Docbook compare can be instructed to do a simple compare (same/different) of such images. Comparing images can be expensive so images are only opened if the fileref locations are determined to be different. It does this using the following steps:
The xml:base of both input files will be used to resolve the fileref to an absolute location. If no xml:base is given the XPAth base-uri() function is used.
The resolved locations from A and B will then be compared for string equality.
If they are the same then the fileref will not be marked as a change
If they are different then the URIs will be opened using URL.openStream and a byte-wise comparison of the images will be done. If any problem occurs then the images will be marked as changed, otherwise the result of the byte-wise comparison will be used to determine whether the image is marked as changed.
You may wish to look at the images from A and B 'side by side' to see what has actually changed. In order to do this use output-image-ref-favour-source-doc. The downside of this is that any mediaobject or inlinemediaobject containing fileref changes will be cloned entirely, and any other changes may be masked.
The result document may reside in a different location to A or B. In order to make it easier to look at the result where it is output and see any image changes, filerefs are changed by default to absolute locations. The compare can be also be configured to use the value from a source document for onward processing. See output-image-ref-form and output-image-ref-favour-source-doc for more detail on this. For more advanced processing of the fileref attribute changes see also modified-attribute-mode and output-format
Currently imagedata entityref changes are not covered by this feature. Imagedata may also contain structured graphics/images (see imagedata.svg). Comparison of these structured images is not treated specially.
{kind=link}
Element Moves
The element moves usually occur due the movement of block level elements, such as paragraphs, to a new location within a document. Due to the use of id attribute values as keys in the DeltaXML DocBook comparison process, these moves result in two copies of the block level item in the output, one marked as deleted (with a suffixed id value for validity) and one marked as added. This does not reflect the level of detail required in the comparison result. Rather than deletion and addition, these should be identified as a move from one location to another. In addition, if the textual content at the target location is also modified as part of the move, these changes should be shown at a fine-grained level of detail i.e. at the word-by-word level.
In order to identify moves, the source section (deleted block) is marked as moved (with a suffixed id value for validity).
When element moves feature is enabled then keying-mode parameter is set to use 'useId' and then the id is converted into a key (the deltaxml:key attribute).
The default state for this new feature is set to disabled. It would need to be explicitly enabled using an API call to make use of it.
MathML Comparison
DocBook 6.0.0 introduced comparison of MathML. This feature allows users of MathML to produce a valid, renderable comparison output if MathML inputs are valid and renderable.
The parameters are mathml-processing and mathml-granularity.
How it Works
Using XML Compare's MathML comparison, users will get an output with changes highlighted using the mathbackground attribute. Delta information is also retained if further processing is required. Note that as we are using mathbackground to display change, this may interfere with and overwrite your own use of mathbackground.
If the comparison finds a <math> element (in the http://www.w3.org/1998/Math/MathML namespace) in an input document MathML comparison is switched on automatically. There is also an option to switch MathML comparison off if you do not require it.
Whitespace is normalised as per instructions in the MathML specification i.e. space between elements is removed, and space within elements is normalised (leading & trailing spaces removed, spaces between words collapsed to a single space).
We have found in testing that Firefox is the best browser for rendering MathML.
Result Granularity
We have provided three levels of granularity of results. To demonstrate the granularity, let's use what should be a familiar formula to many people:
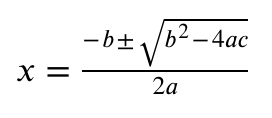
...and make some tweaks...

Inline
Inline mode will mark changes at the lowest level (ie. for MathML elements mi, mo, mn) as possible. This is the default mode. We achieve this by wrapping changes in an <mrow> to keep the number of required arguments in certain elements, e.g. <mfrac>, valid.
Using our example, an inline result will look as such:

Note for example when changing b2 to b3, the change has been wrapped in an <mrow> to keep <msubsup>'s required arguments correct.
If we cannot display the changes inline, we fall back to producing a "detailed adjacent" view to ensure the output is valid and renderable.
Detailed Adjacent
This mode is a side-by-side view that duplicates the inputs, with individual changes highlighted. For readability, we have added a grey background and a small gap between the two formulas.
Here's what our example looks like using this mode:

Adjacent
Adjacent mode is the simplest view and just duplicates the two inputs to give a "before" and "after" view.
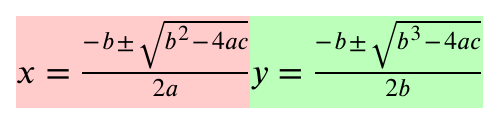
Limitations
MathML has been implemented as an M.V.P to garner feedback from customers. As such, there are various limitations to it:
We are currently only handling Presentation Markup.
Inline comparison will only mark inline changes to
<mi>,<mo>, and<mn>elements.Our comparison presumes your MathML inputs are valid MathML. If they aren't, you may get incorrect results. We may consider validation of MathML inputs in a future release. This would allow us to provide information when inputs aren't valid, and suggest how to fix the errors.
We are currently ignoring changes to MathML attributes and resolving by picking the B version.
Displaying Changes
A DocBook Compare result file contains the information needed to determine the changes between two revisions of a document but in itself it is not able to display those changes in a meaningful way. The next task is to utilise this information in the publishing step for the document so that the changes can be highlighted in formats such as HTML, PDF or even a WYSIWYG editor.
Please note that auto-numbered items such as sections or list items in a document displaying changes may not use the same numbering as in the latest version of the document. This is because deleted items are still given a number. For example, a list that originally had three numbered items but had the middle one deleted will still contain three items in the result but with the middle marked with revisionflag="deleted". When this is converted into a published document, the middle deleted item will be item 2 with the final item being item 3 (rather than 2 as it would be in the latest version of the document).
See the Parameter Definitions in the appendix of the User Guide for details of MathML comparison configuration options.
DocBook Stylesheets (docbook-xsl)
DocBook XSL is a set of stylesheets commonly used for converting DocBook into many different formats such as HTML (single page or chunked), XSL-FO (for processing into PDF), and help page formats. It is highly configurable using stylesheet parameters and it is also customisable, allowing users to redefine how particular DocBook features are processed. To find out more about DocBook XSL, see [docbook-xsl-guide]
HTML Changebars
DocBook XSL comes with the capability to produce an HTML file that uses text coloring and styling to highlight changes. The stylesheet changebars.xsl in the html directory will produce this output for you. The name is slightly misleading as it doesn't actually produce changebars but does color and style the changed text (red background with strikethrough for revisionflag="deleted", yellow background with underline for revisionflag="added" and green background for revisionflag="changed"). These values are not parameterizable but can easily be customised by redefining the system.head.content template. See the next section on DeltaXML Customisation for more details on customising DocBook XSL.
DeltaXML Customisation
Although DocBook comes with the capability to show changes in published HTML, there is not a similar capability for its XSL-FO output (which can subsequently be converted to PDF). DeltaXML have produced a DocBook XSL customization layer that will add changebars and/or text formatting to the XSL-FO output in order to highlight changes marked using revisionflags. The customisation allows the following settings to be configured:
Use of text styling to highlight changes
Color, background, decoration and font style of deleted text
Color, background, decoration and font style of added text
Use of changebars where changes occur
Color and style of changebars
The customisation can be downloaded from our Support and Documentation pages. You will also require a copy of DocBook XSL (which can be downloaded from http://sourceforge.net/projects/docbook/files/ and an FO to PDF converter (we would recommend RenderX XEP or Apache FOP). You can also test out the customisation layer using our DocBook Compare demo - see https://demo.deltaxml.com/compare-demonstration-tool/
oXygen Editor
When editing DocBook files using a WYSIWYG editor, it is sometimes possible to use revisionflag attributes to highlight changes. This section uses the oXygen editor as an example. oXygen can display DocBook in a text view that shows the raw XML or in Author view which uses CSS to display the document in a fashion more like a word processor would display. It is possible to customize the CSS used to display the document in order to use revisionflag values to highlight change.
Since oXygen 14.0. Choose the 'Colored Revison Changes' option from the 'CSS' toolbar.
Prior to oXygen 14.0. To achieve this customisation, first create a file called deltaxml.css in the frameworks/docbook/css directory in your oXygen installation directory. An example listing that highlights added items as green, deleted items as red and modified items as yellow is shown below:
deltaxml.css
@import "docbook.css";
[revisionflag=added] {
background-color: #90ee90;
}
[revisionflag=deleted] {
background-color: #ff5555;
}
[revisionflag=changed] {
background-color: #ffff90;
}Once the file has been created, open the oXygen preferences pane. Select 'Document Type Association' from the list on the left hand side and find the DocBook types in the list that appears (there will probably be separate entries for DocBook 4 and DocBook 5, in which case the following instructions need to be repeated for each).
Change the 'User role' to Developer using the drop-down list at the top.
Select the DocBook entry in the list and press the 'Edit' button
Select the CSS tab and press the + symbol under the list
Enter the URI for the stylesheet (e.g.
${frameworks}/docbook/css/deltaxml.css) and a title for it (e.g. DeltaXML)If you want to keep the standard CSS as the default, select the Alternate checkbox to make this CSS selectable rather than default
Press OK (3 times to close all preference windows).
In Author view for DocBook files you should now be able to select 'DeltaXML' from the CSS drop-down at the top of the window and see changes highlighted as specified.
Parameters Appendix
'Automatic' parameter values
Where parameters can have the value automatic (generally used as the default value for that parameter), their actual value is calculated when the inputs are compared. This calculation is based on the values of other parameters; in the case of DocBook Compare this is typically the 'output-format' parameter. Here, the idea is to set the value used for the parameter to that which is most appropriate for the given output format. When this automatic behaviour is inappropriate, the actual value of each parameter can be manually set to a specific values using the usual mechanisms. See the documentation for the individual parameters for details on what settings will be used.
Parameter Definitions
The parameter names available on the command-line tool and in the APIs are slightly different. In the command-line version, they are written as lower case words separated by a hyphen (e.g. validate-inputs). In the Java API version of the product, they can be accessed using set/get methods that use a camel-cased version of the name (e.g. setValidateInputs and getValidateInputs). In the .NET API version of the product, they are accessed as Properties, again using a camel-cased version of the name (e.g. ValidateInputs). The names used below correspond to the command-line name.
Parameter Summary Table
Parameter | Summary Description |
|---|---|
what type of output is produced | |
whether to validate the input documents if they specify a DOCTYPE | |
whether to make the parser xinclude aware | |
whether to compare text in a more detailed way. | |
whether to detect and handle moves | |
whether to indent the output file. | |
how to process whitespace changes | |
how to report recoverable errors and warnings | |
whether/how to add keys to the input documents | |
if set to 'true', uses -[[old-text]]- +[[new-text]]+ delimiters to show change where is not allowed | |
The comma and-or space separated list of additional phrase elements. | |
whether to ignore any changes that consist only of docbook inline element changes. See inline-formatting-elements | |
A comma and-or space separated list of elements which will be treated as potentially ignorable inline formatting changes. Only active when ignore-inline-formatting is set to true | |
A comma and-or space separated list of elements which will be added to the set in inline-formatting-elements | |
A comma and-or space separated list of elements which will be removed from the set in inline-formatting-elements | |
whether to apply CALS table processing | |
A changed revision flag attribute is added to table cell elements that have changed spans | |
how to process invalid tables | |
whether to apply html table or DITA simpletable processing | |
A changed revision flag attribute is added to table cell elements that have changed spans | |
whether adjacent changes should be grouped | |
the author of the changes | |
the time-stamp when the changes were produced | |
the oXygen editor version | |
how deleted spaces should be handled | |
how changes in tables should be tracked | |
how changes in tables should be tracked | |
how much of the original document information to preserve | |
how to handle data that cannot contain difference markup | |
how modified attributes should be included in the output | |
the version to use in the XML declaration | |
the output character encoding to use in the XML declaration | |
no longer has any effect. This parameter will be removed in a future release. | |
Whether images are compared | |
Whether images changes are propagated to the level of the containing mediaobject | |
The form of imagedata filerefs in the result document | |
Which source imagedata filref, A or B to base the result value on | |
Whether to switch onMathML processing | |
The level of granularity to show | |
Sets whether to do SVG comparison. | |
Specifies the granularity of SVG representation. | |
Sets whether SVG fallback is enabled. | |
Sets fallback change percentage for SVG comparison results. | |
Sets the Input A SVG markup style setting for SVG comparison results. | |
Sets the Input B SVG markup style setting for SVG comparison results. | |
Sets the Z Index SVG markup style setting for SVG comparison results. | |
Set whether SVG Z-Index representation is enabled. | |
Set whether SVG Numeric Tolerance representation is enabled. | |
Sets Numeric Tolerance Value for SVG comparison results. |
output-format. Specifies what type of output is produced.
This parameter can take the following values:
docbook-markup. Differences are marked up using DocBook's revisonflag attribute.
arbortext-tcs. Differences are marked up in the Arbortext tracked change format.
oxygen-tcs. Differences are marked up in the oXygen tracked change format.
xmetal-tcs. Differences are marked up in the XMetaL tracked change format.
The default value is 'docbook-markup'.
validate-inputs. Sets whether to validate input documents.
If set to true and the inputs include a DOCTYPE, they will be validated against it. If they are not valid, the compare method will throw an InputLoadException.
The default value is 'true'.
enable-xinclude. Sets whether the parser will process xincludes.
If set to true the parser will process xincludes while parsing the inputs.
The default value is 'true'.
word-by-word. Sets whether to compare text in a more detailed way.
If set to true , text is split into individual words and so small changes can be shown with greater detail.
The default value is 'true'.
detect-moves. Sets to detect and handle element moves.
The default value is 'false'.
indent. Sets whether the result should be indented.
If run with a compare method that produces a serialized result, a value of yes causes the output to be pretty printed.
This parameter can take the following values:
yes. The value representing the String value 'yes'. Output is indented.
no. The value representing the String value 'no'. Output is not indented.
The default value is 'no'.
whitespace-processing-mode. Specifies how to handle whitespace changes.
When this option is set to 'show' whitespace differences are reported where possible. If the output-format is set to 'docbook-markup' and DocBook doctype is explicitly declared, then the whitespace will be reported wherever the doctype allows text (as opposed to inter-element whitespace). In all other cases, such as when tracked-change output format is selected, all whitespace changes can be shown.
This can lead to a significant amount of marked change throughout the document. When the parameter is set to 'ignore', whitespace differences are not shown; instead the 'B' document's whitespace is kept where possible.
Note that differences in whitespace are never ignored when the XML document explicitly states that the whitespace is important, via the xml:space attribute being set to 'preserve'.
The 'automatic' setting effectively behaves as either 'normalize' or 'ignore' depending on the value of the 'preservation-mode' and the 'output-format' parameters. Here, 'normalize' is chosen when: (1) the lexical preservation mode is set to 'automatic' and the output format is 'docbook-markup'; or (2) the lexical preservation mode is set to either 'document' or 'docAndAttrib'. In all other cases, the automatic preservation mode is treated as if it were 'ignore'.
This parameter can take the following values:
show. Display the differences in whitespace where possible.
cdata. Ignore differences in whitespace, unless they occur within a CDATA section (or are explicitly preserved).
ignore. Ignore differences in whitespace that is not explicitly preserved.
keepA. Similar to 'ignore' except that 'A' document's whitespace is kept (instead of the 'B' document's whitespace).
normalize. Normalize whitespace in inputs before comparison.
automatic. Chooses the most appropriate mode based on other parameter settings. This is dependent on two other parameters 'output-format' and the 'preservation-mode', as discussed in the main whitespace processing mode documentation.
The default value is 'automatic'.
warning-report-mode. Sets the mode to use for reporting recoverable errors and warnings.
This parameter can take the following values:
message. Report the recoverable errors and warnings as XSL messages, which are typically visible when the comparison is run from a command-line terminal.
pis. Add the recoverable errors and warnings as processing instructions.
comments. Add the recoverable errors and warnings as comments.
markup. Add the recoverable errors and warnings as document content.
The default value is 'pis'.
keying-mode. Sets the mode to use for adding keys to the input documents.
Keys can be added to the input documents to force particular parts of the document to match up during a comparison. This method can be used to turn on keying and also gives an option of what to use as keys in the input document.
This parameter can take the following values:
preserve. Use existing deltaxml:key attributes from the input (and nothing else)
useKeyThenId. Use a deltaxml:key attribute if present, otherwise use an id attribute if present
useKeyThenCondition. Use a deltaxml:key attribute if present, otherwise use a condition attribute if present
useId. Use an id attribute if present. Otherwise, do not use a key
useCondition. Use a condition attribute if present. Otherwise, do not use a key
remove. Remove all existing deltaxml:key attributes and do not add any others
The default value is 'preserve'.
show-non-phrase-changes. Sets whether to textually mark changes to text where <phrase>; elements are not allowed.
If text has changed within an element where phrase markup is not allowed, some other means must be used to process the changes. If this parameter is set to true , the changed text is wrapped in textual delimiters e.g. -[[old text ]]- +[[new text ]]+. If the value is set to false, no markup is used and only the new text is output.
The default value is 'true'.
additional-phrase-containers. Sets the comma and/or space separated list of additional phrase elements using Clark notation.
The Clark notation represents an element by a string that has the form '{namespace}localname'. Elements in the default namespace are represented by '{}localname' (or simply 'localname' - thought this is not strictly in Clark notation).
This can be useful in situations where the DocBook has been customized to include some extra elements that contain phrase elements. Adding such elements via this parameter enables these elements to contain changes 'text changes' that are marked up using phrases.
The default value is ''.
ignore-inline-formatting. If set to true , any changes that consist only of the addition, deletion or modification of docbook inline markup elements are not noted as changes.
When comparing the following 2 para versions with ignore-inline-formatting switched on, no changes are marked up
<para>This is an important point</para>
<para>This is an <emphasis>important</emphasis> point</para>
see http://tdg.docbook.org/tdg/5.0/ch02.html#s.inline for a full list of inline markup elements
The default value is 'false'.
inline-formatting-elements. Sets the comma and/or space separated list of inline formatting elements using Clark notation. Only active when ignore-inline-formatting is set to true
This parameter overrides the built in list of docbook inline elements. If the parameter ignore-inline-formatting is set to true then the addition, deletion or modification of these elements will not be treated as changes.
The built in list is shown in the default, it is taken from http://tdg.docbook.org/tdg/5.0/ch02.html#s.inline and the same section for Docbook v4.5. Elements, http://tdg.docbook.org/tdg/4.5/ch02.html#ch02-logdiv
Those elements which do not contain content, such as xref and anchor are not included by default.
The Clark notation represents an element by a string that has the form '{namespace}localname'. Elements in the default namespace are represented by '{}localname' (or simply 'localname' - though this is not strictly in Clark notation). Whitespace in namespace or localname at end or beginning is removed. The occurence of '{' or '}' within namespace or localname is considered an error
The default value is 'abbrev, acronym, emphasis, phrase, quote, trademark, citation, citerefentry, citetitle, firstterm, glossterm, link, olink, ulink, foreignphrase, wordasword, computeroutput, literal, markup, prompt, replaceable, sgmltag, userinput, inlineequation, mathphrase, subscript, superscript, accel, guibutton, guiicon, guilabel, guimenu, guimenuitem, guisubmenu, keycap, keycode, keycombo, keysym, menuchoice, mousebutton, shortcut, action, classname, constant, errorcode, errorname, errortype, function, interface, msgtext, parameter, property, returnvalue, structfield, structname, symbol, token, type, varname, application, command, envar, filename, medialabel, option, systemitem, database, email, hardware, optional, {http://docbook.org/ns/docbook}abbrev, {http://docbook.org/ns/docbook}acronym, {http://docbook.org/ns/docbook}emphasis, {http://docbook.org/ns/docbook}phrase, {http://docbook.org/ns/docbook}quote, {http://docbook.org/ns/docbook}trademark, {http://docbook.org/ns/docbook}citation, {http://docbook.org/ns/docbook}citerefentry, {http://docbook.org/ns/docbook}citetitle, {http://docbook.org/ns/docbook}firstterm, {http://docbook.org/ns/docbook}glossterm, {http://docbook.org/ns/docbook}link, {http://docbook.org/ns/docbook}olink, {http://docbook.org/ns/docbook}foreignphrase, {http://docbook.org/ns/docbook}wordasword, {http://docbook.org/ns/docbook}computeroutput, {http://docbook.org/ns/docbook}literal, {http://docbook.org/ns/docbook}markup, {http://docbook.org/ns/docbook}prompt, {http://docbook.org/ns/docbook}replaceable, {http://docbook.org/ns/docbook}tag, {http://docbook.org/ns/docbook}userinput, {http://docbook.org/ns/docbook}inlineequation, {http://docbook.org/ns/docbook}mathphrase, {http://docbook.org/ns/docbook}subscript, {http://docbook.org/ns/docbook}superscript, {http://docbook.org/ns/docbook}accel, {http://docbook.org/ns/docbook}guibutton, {http://docbook.org/ns/docbook}guiicon, {http://docbook.org/ns/docbook}guilabel, {http://docbook.org/ns/docbook}guimenu, {http://docbook.org/ns/docbook}guimenuitem, {http://docbook.org/ns/docbook}guisubmenu, {http://docbook.org/ns/docbook}keycap, {http://docbook.org/ns/docbook}keycode, {http://docbook.org/ns/docbook}keycombo, {http://docbook.org/ns/docbook}keysym, {http://docbook.org/ns/docbook}menuchoice, {http://docbook.org/ns/docbook}mousebutton, {http://docbook.org/ns/docbook}shortcut, {http://docbook.org/ns/docbook}classname, {http://docbook.org/ns/docbook}constant, {http://docbook.org/ns/docbook}errorcode, {http://docbook.org/ns/docbook}errorname, {http://docbook.org/ns/docbook}errortype, {http://docbook.org/ns/docbook}function, {http://docbook.org/ns/docbook}msgtext, {http://docbook.org/ns/docbook}parameter, {http://docbook.org/ns/docbook}property, {http://docbook.org/ns/docbook}returnvalue, {http://docbook.org/ns/docbook}symbol, {http://docbook.org/ns/docbook}token, {http://docbook.org/ns/docbook}type, {http://docbook.org/ns/docbook}varname, {http://docbook.org/ns/docbook}application, {http://docbook.org/ns/docbook}command, {http://docbook.org/ns/docbook}envar, {http://docbook.org/ns/docbook}filename, {http://docbook.org/ns/docbook}option, {http://docbook.org/ns/docbook}systemitem, {http://docbook.org/ns/docbook}database, {http://docbook.org/ns/docbook}email, {http://docbook.org/ns/docbook}hardware, {http://docbook.org/ns/docbook}optional'.
add-inline-formatting-elements. A comma and/or space separated list of inline formatting elements using Clark notation, which will be added to the value of the inline-formatting-elements parameter
Use this set to add to the value of inline-formatting-elements which you wish to be ignored when considering change processing.
Elements in this set are added to the set in inline-formatting-elements, before the set in remove-inline-formatting-elements is removed.
The default value is ''.
remove-inline-formatting-elements. A comma and/or space separated list of inline formatting elements using Clark notation, which will be removed the list specified in the inline-formatting-elements parameter
Use this list to remove names from the value of inline-formatting-elements when the defaults include elements you wish not to be ignored as changes.
Elements in this set are removed to the set in inline-formatting-elements after the set in add-inline-formatting-elements has been added.
The default value is ''.
cals-table-processing. Specifies whether to apply CALS table processing.
CALS table processing ensures that when valid (both syntactically and semantically according to the OASIS CALS table model documentation) input tables are provided the result will be a valid CALS table.
Simple changes to the table, such as changing the contents of an entry, adding a row or column are generally represented as fine grain changes. Because CALS entries can overlap or span multiple rows and columns, some types of change are difficult to represent at fine granularity, whilst ensuring validity. In these cases changes are represented at row (ie, groups of added/deleted rows) or even whole-table granularity.
Setting this parameter to false turns off this processing, therefore it is possible to generate an invalid table. However, if table validity is not a concern changes may be represented at finer granularity.
The default value is 'true'.
mark-cals-table-cell-span-extent-changes.
When set, a changed revision flag attribute is added to table cell elements that have changed spans.
invalid-table-behaviour. In order to ensure that only valid CALS tables are passed to our specialized CALS table processing, each input table is marked either valid or invalid. This parameter declares what type of processing should be used for those tables that are marked as invalid. The 'warning report mode' parameter configures how recoverable errors are reported.
Three options are provided: fail, propagate up, and compare as XML. The fail option stops the comparison by throwing an appropriate exception (that includes the errors identified by the validity checker). The propagate up option ensures that changes to an invalid table (or more specifically 'tgroup') are represented at the table level. The compare as XML option essentially compares the tables as if they were well-formed XML.
Note that the results of the compare as XML option can differ from comparing the tables without CALS table processing enabled, as a small amount of CALS specific processing is applied to invalid tables in order to allow them to be compared against a similar valid table.
This parameter can take the following values:
fail. Throw an exception.
propagateUp. Propagate the changes to the table-level.
compareAsXml. Compare the table content as well-formed XML.
The default value is 'propagateUp'.
html-table-processing. Specifies whether to apply html table (otherwise known as DITA simpletable) processing.
HTML tables processing ensures that when valid input tables are provided - according to the HTML-4 or draft HTML-5 documentation - the result will be a valid HTML-4/5 table. Note that both inputs need to follow the same standard (ie be HTML-4 or HTML-5).
Simple changes to the table, such as changing the contents of a cell and adding a row or column are generally represented as fine grain changes. Because HTML entries can overlap or span multiple rows and columns, some types of change are difficult to represent at fine granularity, whilst ensuring validity. In these cases changes are represented at row (ie, groups of added/deleted rows) or even whole-table granularity.
DITA Simple tables are also handled by this filter. In this case, the syntactic constraints ensure that cells cannot overlap or span either rows or columns, therefore changes are represented at a fine grained level of detail.
Setting this parameter to false turns off this processing, therefore it is possible to generate an invalid table. However, if table validity is not a concern changes may be represented at finer granularity.
The default value is 'true'.
mark-html-table-cell-span-extent-changes.
When set, a changed revision flag attribute is added to table cell elements that have changed spans.
grouping. Specifies whether adjacent changes (insertions or deletions) should be grouped into a single insertion and/or deletion block. One benefit of this is that changes to a consecutive group of words within a sentence are gathered into one insertion and one deletion block, rather than a series of individual word swaps. This makes it easier to read and understand the changes.
Note that when either HTML or CALS table processing modes are selected, then this grouping mechanism is turned off within the context of these tables. The table processing has its own specialised grouping mechanisms.
The default value is 'false'.
tracked-changes-author. Specifies the author name that is embedded into the generated insertion and deletion processing instruction.
The default value is 'deltaxml'.
tracked-changes-date. Specifies the time-stamp that is embedded into the generated insertion and deletion processing instruction. The default time-stamp is that of the time that the comparison is run.
The default value is 'xsl date'.
oxygen-tcs-version. Specifies the version of oXygen editor used to display, accept and reject the tracked changes.
The format of the version is either '[0-9]+' or '[0-9]+.[0-9]+' without the enclosing string quotes, where: the first number sequence is the major number; and the optional second number sequence is the minor number.
This parameter is used to automatically set the relevant backwards compatibility options related to the oXygen tracked changes format. For example, prior to oXygen 14.0 release deleted whitespace needed to be normalised in order to consistently generate a reasonable result.
The default value is '11.2'.
oxygen-tcs-deleted-space-mode. Specifies how deleted spaces should be handled.
Prior to oXygen 14 whitespace within the deleted content of a processing instruction were sometimes not displayed correctly. A work-around was to normalise the space within a deleted region.
This parameter can take the following values:
automatic. Chooses the delete space processing mode based on the declared oxygen-tcs-version parameter.
normlize. Allows deleted text to be viewed correctly prior to oXygen 14 release.
keep. Keeps the original whitespace formating of the deleted region.
The default value is 'automatic'.
xmetal-tcs-table-change-mode. Specifies how changes in tables should be tracked.
The XMetaL editor cannot track the addition or deletion of a row or cell within a table. Such changes can be pushed down to the cell level, pushed up to the table level (e.g. a CALS or HTML 'table' element), or ignored. The advantage of pushing the changes down to the cell content level, is that this provides the highest level of change granularity, at the cost of having to accept or reject every changed cell in the table independently.
The push up processing means that any table that contains a row or cell level update is represented by a table level add and delete.
The ignore option is similar to the way in which track changes within tables are handled in XMetaL; as neither row insertion and deletion or cell splitting and merging is tracked. However, for clarity this mode of operation ignores all changes within a table, it simply produces the 'B' version of the table.
This parameter can take the following values:
down. Changes in rows and cells are pushed down to the cell content level.
up. Changes in rows and cells are pushed up to the table level.
ignore. All changes in a table are ignored.
The default value is 'down'.
framemaker-tcs-table-change-mode.
Specifies how changes in tables should be tracked.
The FrameMaker editor cannot track the addition or deletion of a row or cell within a table. Such changes can be pushed down to the cell level, pushed up to the table level (e.g. a CALS or HTML 'table' element), or ignored. The advantage of pushing the changes down to the cell content level, is that this provides the highest level of change granularity, at the cost of having to accept or reject every changed cell in the table independently.
The push up processing means that any table that contains a row or cell level update is represented by a table level add and delete.
The ignore option is similar to the way in which track changes within tables are handled in FrameMaker; as neither row insertion and deletion or cell splitting and merging is tracked. However, for clarity this mode of operation ignores all changes within a table, it simply produces the 'B' version of the table.
This parameter can take the following values:
down. Changes in rows and cells are pushed down to the cell content level.
up. Changes in rows and cells are pushed up to the table level.
ignore. All changes in a table are ignored.
The default value is 'down'.
preservation-mode.
Sets the mode to use for preserving original data.
This mode can be used to preserve information for round trip processing.
The 'automatic' setting will have an effective setting of 'roundTrip' when the output format is a tracked change format and 'docAndAttrib' otherwise.
This parameter can take the following values:
automatic. Chooses the most appropriate setting based on the output format. If tracked changes are being produced, this will be 'roundTrip', otherwise 'docAndAttrib' will be used.
document. Preserve document typing information.
docAndAttrib. Preserve document typing and original attribute information.
roundTrip. Preserve document type, entity usage, and attribute usage data.
entityRef. Enhance round-trip processing by analysing entity contents.
nestedEntityRef. Enhance round-trip processing by analysing both entity and nested entity contents.
The default value is 'automatic'.
xml-version-declaration. Sets the version to use in the XML declaration.
The 'system' special value is introduced; selecting it has the affect of choosing 'B' document's xml-version (as provided by the parser).
This parameter can take the following values:
1.0. Ensure the xml version is set to '1.0'.
1.1. Ensure the xml version is set to '1.1'.
system. Use the 'B' document's xml version (as provided by the parser).
The default value is 'system'.
output-encoding-declaration. Sets the character encoding output to use in the XML declaration. For example, 'UTF-8', 'ISO-8859-1', 'windows-1252', and 'ascii'. Precisely which encodings are available is dependent on the specific Java or .NET runtime environment that you use. Note that an invalid output encoding will cause an exception to be raised.
The 'system' special value is introduced; selecting it has the affect of choosing the 'B' document's character encoding.
The default value is 'system'.
standalone-declaration. This parameter no longer has any effect. Preserving the standalone declaration is not supported, due to incompatibilities in the underpinning parsing and serialisation technologies.
This parameter can take the following values:
yes. Ensure the standalone attribute is set to 'yes' in the output XML declaration.
no. Ensure the standalone attribute is set to 'no' in the output XML declaration.
omit. Ensure there is no standalone attribute in the output XML declaration.
system. Deprecated: has the same affect as the omit value.
The default value is 'omit'.
image-compare. If set to true, the physical locations and possibly the actual images used will be compared rather than the string value of the location (fileref attribute) of the imagedata
In docbook terms imagedata element fileref attributes will be resolved to absolute locations and tested for equality. If they are not equal fileref URIs will be opened and the streamed image content will be compared byte by bte for equality.
This can mean that even though the fileref has not changed the image will be marked as a change if it resolves to different images within the context of A or B. Similarly if the fileref has changed but resolves to the same image within the context of A or B it will not be marked as a change.
The xml:base of both input files will be used to resolve the fileref to an absolute location. If no xml:base is given the XPAth base-uri() function is used. The resolved locations from A and B will then be compared for string equality. If they are the same then the fileref will not be marked as a change, if they are different then the URIs will be opened using URL.openStream and a byte-wise comparison of the images will be done. If any problem occurs then the images will be marked as changed, otherwise the result of the byte-wise comparison will be used to determine whether the image is marked as changed.
See also
The default value is 'false'.
show-image-changes-at-mediaobject-level. If image-compare is set to true and determines that images have changed, show the changes as changes to the containing mediaobjects.
By default image changes are tracked as changes to the fileref attribute of the DocBook imagedata tag. Since changes to attributes are difficult to show in docbook, it may be preferable to show the change at the level of the containing mediaobject or inlinemediaobject by cloning them and showing the A and B versions as neighbouring siblings in the result document.
The default value is 'false'.
output-image-ref-form. If image-compare is set to true, this parameter controls the form output for fileref attributes of imagedata elements
This parameter can take the following values:
absolute. the value will be the absolute location used to calculate whether the image has changed. This should mean that for filesystem filerefs at least the images should be visible in the result document. See image-compare for more detail on how the absolute form is calculated.
source. the value will be as it appears in the source A or B document. See output-image-ref-favour-source-doc
The default value is 'absolute'.
output-image-ref-favour-source-doc. If image-compare is set to true, this parameter controls which imagedata fileref attribute, from A or B is use to derive the result fileref value when the image has not changed
If image-compare is set to true and there are no differences in the A and B images, this determines which of the source Documents, A or B, will be used to set the value of the result fileref . This value will then be used as is or be turned into an absolute value depending on the value of output-image-ref-form
If images are identical it can still be the case that filrefs for A and B can point to different files, so there is a choice of the value used to derive the result, also if output-image-ref-form is set to 'source' the string values of the fileref attributes can be different.
For images that HAVE changed the value used in the result will be controlled by modified-attribute-mode. This generally defaults to the B value, so if you change output-image-ref-favour-source-doc it might be wise to change modified-attribute-mode as well.
This parameter can take the following values:
A. The value from the 'A' source document will be used
B. The value from the 'B' source document will be used
The default value is 'B'.
mathml-processing. When set to true MathML elements will be processed according to the granularity setting.
Setting this parameter to false turns off this processing, therefore it is possible to generate an invalid output. However, if MathML validity is not a concern changes may be represented at finer granularity.
The default value is 'true'.
mathml-granularity. This parameter allows you to choose the way that MathML differences are displayed. See the MathML section for examples.
This parameter can take the following values:
adjacent
detailed-adjacent
inline
The default is 'inline'.
svg-processing
Sets whether to do SVG comparison. SVG comparison is recommended as it will use SVG XML-aware features when comparing two SVG images to ensure that the result can be rendered.
svg-granularity
Specifies the granularity at which the differences between two SVG images will be represented. SVG Granularity can be of three types - ‘detailed-adjacent', ‘adjacent', and 'animate-inline’. The default is 'detailed-adjacent’.
‘adjacent' reports the differences by repeating A and B SVG adjacent to each other.
'detailed-adjacent' reports the differences by repeating the A and B SVG adjacent to each other. Content within the adjacent A and B views is highlighted at the specific parts where it is different.
'animate-inline’ reports SVG differences by animating them by changing the opacity from 1 to 0 for delete and 0 to 1 for add. This setting will override any other SVG configuration.
svg-fallback
Set whether SVG fallback is enabled. SVG comparison granularity will fallback to SVGComparisonGranularity.ADJACENT if SVG exceeds the number changed elements defined by FallbackChangePercentage.
svg-fallback-change-percentage
Sets fallback change percentage setting for SVG comparison results. The default value is 30.00%.
input-a-svg-markup-style
Sets the Input A SVG markup style setting for SVG comparison results. The default is "red" and an SVG color can be provided as color names, RGB or RGBA values, HEX values, HSL or HSLA values.
input-b-svg-markup-style
Sets the Input B SVG markup style setting for SVG comparison results. The default is "green" and an SVG color can be provided as color names, RGB or RGBA values, HEX values, HSL or HSLA values.
z-index-svg-markup-style
Sets the Input Z SVG markup style setting for SVG comparison results. The default is "purple" and an SVG color can be provided as color names, RGB or RGBA values, HEX values, HSL or HSLA values.
svg-z-index
Set whether SVG Z-Index representation is enabled. Uses move handling within SVG Comparisons to markup Z-index changes.
svg-numeric-tolerance
Sets whether to use SVG numeric tolerance. SVG comparison will check co-ordinate values are within specified tolerance and therefore can be considered having negligible change.
svg-numeric-tolerance-value
Sets the numeric tolerance value for SVG comparison results. The default is 1%, but can be given as a fixed value. Adding '%' will switch value to percentage.
Configuration Properties
Table B.1. Configuration Property Summary Table
Property Name | Summary Description - See below for more details |
|---|---|
com.deltaxml.cmdline.forceOverwrite | whether the command line tool overwrites output files without prompting |
com.deltaxml.docbook.DocBookCompare.debug | whether the intermediate results are produced for debugging |
com.deltaxml.docbook.DocBookCompare.timing | whether times for processing each filter are produced to stdout |
com.deltaxml.ext.catalog.files | the external catalog files to be searched |
xml.catalog.files | the catalog files to be searched |
com.deltaxml.rsc.catalog.files | the fixed internal catalog files to be searched |
java.property.name | provide the initial value for an unset java property. |
com.deltaxml.cmdline.forceOverwrite. Specifies whether the command line tool overwrites output files without prompting.
The default value is 'false'.
com.deltaxml.docbook.DocBookCompare.debug. Specifies whether the intermediate results are produced for debugging.
When set to true all 'non-optimised' processing stages have an intermediate result associated with them, in the form of a file with name 'DocBookCompare__<stage name>.xml'. Some filters in the pipeline processing are optimised by essentially merging their processing; in these cases the result of the merged filters is produced.
This output is only intended for use when directed by DeltaXML support staff.
The default value is 'false'.
com.deltaxml.docbook.DocBookCompare.timing. Specifies whether times for processing each filter are produced to the standard-output/console.
When set to true the time it taken by each of processing stages is recorded. Note that a zero time duration indicates one of two situations, either the stage was too fast to register a time, or more likely that stage has been 'optimized' (merged into another stage) and so is included in another stages results.
This output is only intended for use when directed by DeltaXML support staff.
The default value is 'false'.
com.deltaxml.ext.catalog.files. Specifies the external catalog files to be searched.
The tool is preconfigured to include the catalog's for supported document versions. However, this mechanism provides a means for supplementing/overriding given catalog entries with a user defined catalog.
Note that this property can be bypassed by directly changing the default definition of the more general xml.catalog.files property below.
The default value is '' (the empty string).
xml.catalog.files. Specifies the catalog files to be searched.
This string provides a mechanism for setting the underpinning Apache XML commons resolver's catalog search path. Note that as this is a Java system property, it can be overridden on the command-line via use of the -Dxml.catalog.files=value JVM argument (or environmental setting). In general, this mechanism will only set the property, if it does not already exist.
Note changing the catalog files, can change what it means for a document to be valid, and thus affect the way in which the document comparison processing should be performed. For example, it can affect the allowed order of elements. Therefore, it is not possible for the tool to guarantee that valid inputs result in valid outputs if its catalog(s) have be modified or replaced.
The default value is '${com.deltaxml.ext.catalog.files};${com.deltaxml.rsc.catalog.files}'.
com.deltaxml.rsc.catalog.files. Specifies the the fixed internal catalog files to be searched.
This property cannot be modified, but can be referenced to enable the internal catalogs to be searched. By default the xml.catalog.files (see above) searches this catalog after any external catalog supplied by the user, via the com.deltaxml.ext.catalog.files property, has been searched.
java.property.name. Provide the initial value for an unset java property.
It is possible to use a deltaxmlConfig.xml file to provide arbitrary Java system properties, so long as they do not already have a definition provided, such as one provided by a JVM argument (-Djava.property.name=value) or the environment. For example it is possible to specify the Apache catalog verbosity by setting the initial value of the xml.catalog.verbosity system property. This can be useful for seeing which the catalog(s) are actually being loaded and used.
In general, this mechanism will only set the property, if it does not already exist.
Resources
XML Resources
[xml-W3C] http://www.w3.org/XML. W3C Consortium site for all XML specifications and news.
[xml-spec] http://www.w3.org/TR/REC-xml. The formal specification for XML.
[xml-model] http://www.w3.org/TR/xml-model/. W3C Working Group Note on xml-model processing instruction.
[xml-intro] https://www.w3schools.com/xml/. W3 Schools introduction to XML.
DeltaXML Resources
[dxml-keying] (11.0) Using Keys with Ordered Data. Explanation of keying documents for comparison with XML Compare.
General DeltaXML documentation is published here.
A list of available DeltaXML Downloads is available here.
See a tailored comparison for DocBook Compare.
DocBook Resources
[docbook-4-tdg] http://www.docbook.org/tdg/en/html/docbook.html. DocBook 4: The Definitive Guide.
[docbook-5-tdg] http://www.docbook.org/tdg5/en/html/docbook.html. DocBook 5: The Definitive Guide.
[docbook-xsl] http://wiki.docbook.org/DocBookXslStylesheets. The DocBook XSL Stylesheets.
[docbook-xsl-doc] http://wiki.docbook.org/DocBookXslStylesheetDocs. The DocBook XSL Stylesheets Documentation.
[docbook-xsl-download] http://sourceforge.net/projects/docbook/files/. DocBook XSL download page.
[docbook-xsl-guide] http://www.sagehill.net/docbookxsl/index.html. DocBook XSL: The Complete Guide.
[docbook-xsl-custom] http://www.sagehill.net/docbookxsl/CustomizingPart.html. Customising DocBook XSL section in DocBook XSL: The Complete Guide.