
Document Comparator Guide
Introduction
The Document Comparator is a top-level component in XML Compare, first introduced in version 7.0. It provides a set of document comparison features that are customisable to meet your specific needs. Designed for integration with other systems, the Document Comparator is accessed through the DocumentComparator class in the Java for XML Compare. A DocumentComparator class can also be created using DCP XML via the DCPConfiguration class.
This guide serves as an overview of the Document Comparator. It explains when you should use it, its key capabilities, how it can be configured and extended, how comparisons are run, and how the comparison result can be used.
The XML Compare User Guide provides more general information on XML Compare as a whole. It covers subjects such as comparison concepts, system configuration, and licensing. More detailed information on specific Document Comparator features and how they can be customized can be found in the respective Java API documentation. The DCP Schema Guide and DCP User Guide together describe how the Document Comparator Pipeline (DCP) XML format is used to customize the Document Comparator.
Choosing a Comparator
Besides the Document Comparator, the other main component in XML Compare API is the Pipelined Comparator, implemented through the PipelinedComparatorS9 class.
The Pipelined Comparator is a flexible XML comparison toolkit. It provides an XML comparator placed within a pipeline to which XSLT or Java filters can be added at any point within the input or output streams. A set of documented filters is supplied for use in the pipeline.
The Document Comparator is an extension of the Pipelined Comparator designed specifically for comparing documents. As a more specialist solution, it therefore incorporates many filters directly into the pipeline that would otherwise have to be added manually. It also allows for more sophisticated capabilities to be exposed through a simple API. Considerable extensibility is still available should it be required, using DCP or through the API, but the default settings are tailored for document use so that the user is freed from having to understand all the settings.
If the XML you're comparing is predominantly document-based then the Document Comparator would in most cases be preferred to the Pipelined Comparator. That said, the flexibility of the Pipelined Comparator may still offer benefits if you have experience and resources available from previous projects based on this component.
Document Comparison
While XML is used for conveying information for a range of diverse purposes, the Document Comparator is optimized specifically for XML content that is predominantly narrative in nature, such as an article or book. To understand why a specialist comparison is needed for this type of XML, it's helpful to first look at the different characteristics of XML elements typically encountered in a document:
Structure
Structure elements divide documents into a hierarchy, often with titled sections.
Highly structured elements, such as tables, need to conform to a set of rules to be valid.
Some elements have child elements whose order is not significant (it normally is).
Structural elements may be uniquely identifiable, often with a dedicated id attribute.
Content
Elements may link to other documents or resources such as images.
Some elements are predominantly for styling the document, either inline or at the block level.
Whitespace differences are significant in some elements, but not all.
Certain elements may have content with automated changes that are ignorable.
Text within many elements is of a narrative form, with words and punctuation.
The list of document element characteristics above is grouped according to whether they're related to the structure or content of a document. A document comparison can be customized so that these characteristics are identified for the elements of a specific document type, and therefore improve the effectiveness of the result.
Performing a comparison
Invoking the comparison
Comparisons using the Document Comparator can be invoked either from the command-line, GUI, or REST API using DCP or by using the Java API via the compare method of a DocumentComparator object instance. This method is overloaded to cater for a wide range of use cases.
Before invoking the compare method, the DocumentComparator instance is configured for the specific comparison required. Options can either be set on the DocumentComparator object directly using Java, or through a DCP XML file using a DCPConfiguration object.
Using Java Only
// inhibit 'Cannot find CatalogManager.properties' warning
System.setProperty("xml.catalog.files", "");
// create DocumentComparator instance
DocumentComparator dc= new DocumentComparator();
// setting a readability option
dc.getResultReadabilityOptions().setElementSplittingEnabled(false);
// initialize files
File f1= new File("input/file1.xml");
File f2= new File("input/file2.xml");
File result= new File("output/result.xml");
// invoke comparison
dc.compare(f1, f2, result);
Using Java with DCP XML for configuration
// inhibit 'Cannot find CatalogManager.properties' warning
System.setProperty("xml.catalog.files", "");
// reference an existing DCP configuration file
File dcpFile= new File("configurations/standard-1.dcp");
// initialize configured DocumentComparator instance
DCPConfiguration dcpConfig= new DCPConfiguration(dcpFile);
dcpConfig.generate();
// initialize files
File f1= new File("input/file1.xml");
File f2= new File("input/file2.xml");
File result= new File("output/result.xml");
// invoke comparison
dcpConfig.getDocumentComparator().compare(f1, f2, result);Monitoring progress
Under certain conditions document comparisons can take a while to complete. In such cases, the end-user can be informed of progress using a 'listener'. A listener is an instantiated object that implements the DocumentProgressListener interface; this can exploit data passed in call-back methods from the Document Comparator to relay progress back to the user. The listener is associated with the DocumentComparator using its addDocumentProgressListener method.
Pipeline diagnosis
When developing new filters to add to a pipeline, it is often useful to isolate the behaviour of each filter. To achieve this, the Document Comparator can serialize the output from every filter in the pipeline to a separate file. These files are named to match filter steps and arranged in a directory structure to reflect that of the filter chains in the pipeline.
By default, pipeline diagnosis is disabled. To enable it, the DebugFiles property of the DocumentComparator is set to true. This property can also be controlled as an XML Compare configuration property using its fully qualified name com.deltaxml.cores9api.DocumentComparator.debugFiles. See the XML Compare user guide for more information on this property.
Customizing a comparison
The Document Comparator comprises a standard comparator engine that lies at the centre of a processing pipeline that links together a series of input and output filters. The filters are simple transforms that each modify the input for a specific purpose to produce the required output. Filters can be implemented in XSLT or Java.
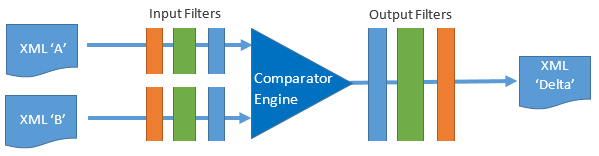
For customization, filters can either be internal and controlled via DocumentComparator properties, or they can be external XSLT or Java resources. The external filters are managed via the Document Comparator API as FilterStep and FilterChain objects that are added at named extension points in the comparison pipeline. The extension points allow external filters to fit in with the behaviour of internal filters and are illustrated in the diagram below:
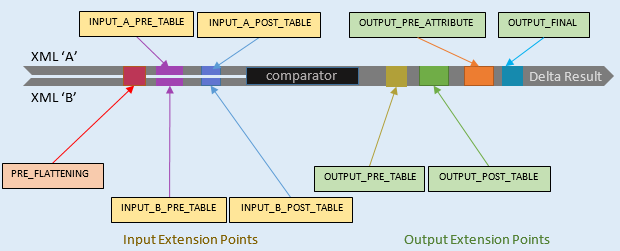
A FilterChain consists of a sequence of 1 or more FilterStep objects. Since a FilterChain is a type of FilterStep, it can in turn be added to another FilterChain instance.
A filter, normally coded in XSLT, is typically dedicated to a single task such as adding an attribute for elements that match a certain pattern. More detail on writing and adding a filter to the comparison pipeline can be found at Appendix I - Custom Filters.
Types of customization
Customization improves comparisons for a range of purposes that can be broadly categorized as: Input, Readability and Output. The sections below describe each of these categories in turn.
Input Customization
The Document Comparator, provides 'out of the box' comparison behaviour designed for general input document characteristics; but, as outlined in the Document Comparison section, a comparison tailored to the element characteristics of a specific document type will yield significantly improved results.
Standard behaviour:
Word by Word
Differences in all elements are resolved down to the word level - unless an deltaxml:word-by-word="false" attribute is found on the element. The Word By Word Text Comparison sample shows the result of an XSLT filter being used to disable the word-by-word feature. Note that word-by-word exploits word-splitting based on the icu4j Java library, from the International Components for Unicode (ICU).
Whitespace Normalization
When applied, sequences of whitespace characters are normalized to a single space character - unless an xml:space="preserve" attribute is in scope on a containing element. Text nodes that contain only whitespace characters are treated differently when they are found to be children of mixed-content elements. The Managing White Space guide covers this subject in more detail.
Formatting Elements
All elements annotated with an deltaxml:formatting="true" attribute are 'flattened' for comparison purposes and then reconstructed post-comparison. This allows changes to formatting elements to be marked differently and therefore treated specially in an output filter. The default behaviour is to only show the formatting elements from the 'B' document with formatting from the 'A' document where there is no conflict; this is demonstrated in the Formatting Element Changes sample.
The OutputFormatConfiguration.ModifiedFormatOutput property can have values of 'A', 'B', 'AB' or 'change', the default value is 'BA'. When ModifiedFormatOutput is set to 'change', the formatting elements for both documents are represented using special DeltaV2.1 format elements. See the Javadoc or the DCP Schema Guide for more details.
Table Processing
Elements conforming to the HTML and CALS specifications are recognized and processed specially to keep the output valid, provided the input is valid.
See Configuration for Processing HTML Tables and Configuration for Processing CALS Tables for full details.
For a detailed discussion of table processing with examples see Comparing Document Tables
Comparison Order
The standard behaviour is for the comparator to match elements based on their document order. This behaviour can be tailored to match different elements via any of the following methods.
Use the
deltaxml:ordered="false"attribute on an element whose child element can appear in any order without affecting their meaning.Add an
deltaxml:key="value"attribute, where the value is a unique identifier for aligning a specific element occurring in both input documents.Sort the child elements of a specific element type using a custom sort key prior to comparison.
The result of orderless comparisons is controlled by the 'OrderlessPresentationMode' property of the OutputFormatConfiguration class. See the API documentation for full details on this.
The Comparing Orderless Elements and Detecting and Handling Moves samples both demonstrate the Document Comparator being used to process orderless data embedded within a document.
The principle of using deltaxml:key="value" attributes with ordered data and mixed ordered/orderless data is shown in the Using Keys with Ordered Data sample and Mixed Ordered and Orderless Data guide respectively.
Ignored/Merged Changes
Changes matching a certain pattern may be ignorable, or in other cases they may override the original content. An output filter can mark such changes with an deltaxml:ignore-changes attribute, where the attribute value determines the keep/override behaviour. A practical example of how this feature is used can be found in the Ignoring Changes sample.
Note 1: The sample referenced above uses the Pipelined Comparator, so although the filters are the same, they are added to the pipeline and run differently when using the Document Comparator.
Note 2: This feature is not intended for elements marked as 'formatting elements' - use the 'Ignoring Formatting Changes' feature instead.
Altering standard behaviour
The above description of standard input behaviours described the attributes or 'markers' that can be added to customize behaviour. With the exception of Ignored/Merged Changes, these are all added prior to comparison, i.e. in 'marker' input filters.
Readability Customisation
In some contexts, a non-optimized comparison result may be cluttered or hard to interpret. The Document Comparator exploits a number of features to enhance the readability of results - without affecting their correctness. These features can be fine-tuned to specific content via the ResultReadabilityOptions class, the default property values for this are given in Appendix II. An overview of the readability options is given below:
ResultReadabilityOptions
Element Splitting
Elements from two input documents may align mainly due to structure, with minimal shared text content. Moreover, text matches that do occur may be coincidental.
In such cases, it can cause confusion if the result is represented as a single element with many text changes, interspersed with matching text. Here the strategy is to split the modified element into two when the amount of shared text falls below a given percentage.
Note
To preserve change information on keyed elements, element splitting is never applied to elements with a deltaxml:key attribute.
Orphaned Word Detection
When comparing text from corresponding parts of two documents, there may be changes to a whole phrase, but with common words such as 'the' matching. Such words are said to be 'orphaned' from the rest of the phrase they belong to. With Orphaned Word Detection, these words can be associated back with the larger phrase to which they belong allowing the change to be read as a whole.
Change Gathering
This applies to changes at any level of the XML tree. The concept is also referred to as 'red-green filtering' in parts of the documentation. When sibling elements or text are a mix of added and deleted content, it is by default reordered to show all deleted content followed by all added content. The ChangeGatheringEnabled property can be set to false to disable this behaviour at the element level, however, word level change gathering is always enabled.
Modified Whitespace
In this case, the result is considered modified if, and only if, both documents have some whitespace at the same point which differs. This method also provides an option for whitespace normalization that is applied to the input documents.
Output Customization
A further reason for customization is to produce an output format designed for a specific purpose or tool.
Lexical Preservation
The default behaviour for the Document Comparator is, where possible, to preserve the lexical properties (i.e. the literal text) of the original XML files in the output. For example, entity references are kept intact as references rather than being resolved to literal values. Lexical Preservation is affected through the LexicalPreservationConfig property that is initially set to PresetPreservationMode.ROUND_TRIP.
This standard lexical preservation should meet the requirements for many cases, but customization is available for specific output formats. This is described in the Lexical Preservation guide.
Ignoring Formatting Changes
The Input Customization section describes how elements used predominantly for formatting in a particular input document type can be marked as such. The Document Comparator defaults to hiding changes to these marked formatting elements by showing only those in the 'B' document - with one exception: when the containing element such as a paragraph is present in the 'A' document but not in the 'B' document (i.e. the paragraph was deleted as a whole). This is initialized to ModifiedFormatOutput.AUTOMATIC through the ModifiedFormatOutput property of the OutputFormatConfiguration object.
Grouping
The grouping parameter enables you to choose whether to group adjacent changes together or not. By default the Document Comparator does group adjacent changes together.
Output Formats
The 'raw' result of the Document Comparator is the 'Delta'. It has the look and feel of the original input documents, but with annotations added to describe the differences. This is the standard output, but other output formats can be produced:
Tracked Change Formats
The Tracked Changes formats of the ArborText, FrameMaker, Oxygen and XMetal XML editors. The OutputFormatConfiguration object has a ResultFormat property that is used to set the tracked changes format. This object has other properties for setting author and date-time data in the tracked-changes format. For more details see here.
Custom Output Formats
Custom output formats can be created by adding an XSLT output filter to perform a final transform on the chosen pre-defined output format or, perhaps more commonly, on the raw Delta format. XML Compare includes output filters for either a 'side-by-side' or a 'folding' html rendering, called a 'DiffReport'. Sample code for adding an XSLT output filter to the pipeline is included in Appendix I.
Viewing a comparison result
The raw Delta output from the Document Comparator needs to be transformed to a suitable output format to allow the end-user to interpret the result most effectively. This format can be for viewing in a web browser, opening in an XML authoring tool, opening in a specialist reviewing tool, or perhaps ultimately printing to paper.
The Output Formats section above provides more detail on the pre-defined output formats available from the Document Comparator.
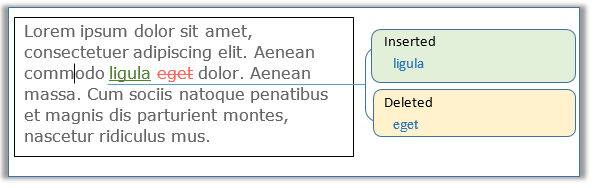
Appendix I - Custom Filters
Writing an XSLT filter
Most filters are coded in XSLT and will normally exploit DeltaXML's internal Saxon processor which supports XSLT 2.0 and 3.0. Here is a sample input filter (XSLT 2.0) that performs an 'Identity Transform' matching li elements with xml:id attributes and adding an xsl:key attribute to hold the xml:id value:
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:deltaxml="http://www.deltaxml.com/ns/well-formed-delta-v1">
<xsl:template match="@* | node()">
<xsl:copy>
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="li[@xml:id]">
<xsl:copy>
<xsl:attribute name="deltaxml:key" select="@xml:id"/>
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Adding a filter to the pipeline
Once written, the XSLT filter needs to be added to the Document Comparator pipeline using the DocumentComparator API, here's some sample Java code showing this:
DocumentComparator dc= new DocumentComparator(saxonProcessor);
FilterStepHelper fsh= dc.newFilterStepHelper();
FilterChain outFc = fsh.newFilterChain();
FilterStep fsSBS= fsh.newFilterStepFromResource(
"xsl/dx2-deltaxml-sbs-folding-html.xsl", "side-by-side");
outFc.addStep(fsSBS);
dc.setExtensionPoint(ExtensionPoint.OUTPUT_FINAL, outFc);Note
In the above example the FilterStep is created using the newFilterStepFromResource method to access one of the XSLT filter files included within XML Compare; the newFilterStep method is used to access external files.
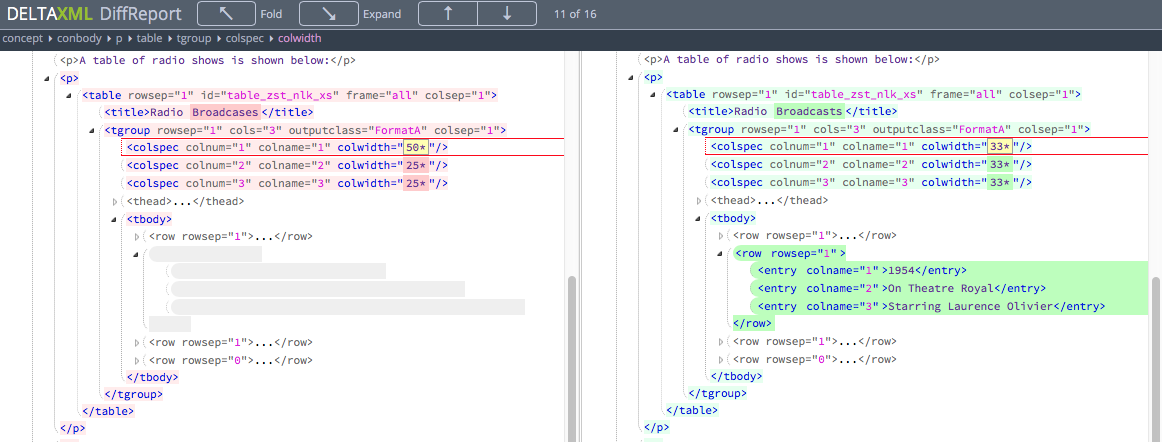
Screenshot of a side-by-side DiffReport created with the dx2-deltaxml-sbs-folding-html.xsl output filter:
Filters can also be added using a DCP pipeline definition, the following DCP uses the 'folding' DiffReport stylesheet to format the output:
<documentComparator version="1.0" id="dcp-folding"
description="Render result as folding html view." >
<extensionPoints>
<outputExtensionPoints>
<finalPoint>
<filter>
<resource name="xsl/dx2-deltaxml-folding-html.xsl"/>
</filter>
</finalPoint>
</outputExtensionPoints>
</extensionPoints>
</documentComparator>
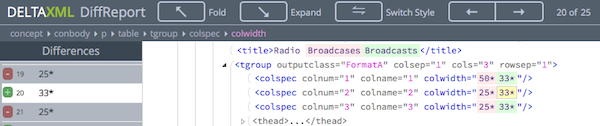
Screenshot of a 'folding' DiffReport created with the dx2-deltaxml-folding-html.xsl output filter:
Appendix II - Default Configuration
The Document Comparator is pre-configured using default settings. The default settings are summarized in the table below, more details can be found in the API documentation, links to the corresponding classes can be found in the 'Class' column.
Class | Property | Default Value | Range/Type |
|---|---|---|---|
DebugFiles | false | boolean | |
DebugPrefix | 'deltaxml...' | string | |
PresetPreservationMode | ROUND_TRIP | (see API docs) | |
ProcessCalsTables | true | boolean | |
ProcessHtmlTables | true | boolean | |
CalsTableBehaviour | PROPAGATE_UP | FAIL COMPARE_AS_XML | |
CalsValidationLevel | RELAXED | STRICT | |
ElementSplittingEnabled | true | boolean | |
ElementSplittingThreshold | 10 | 1 to 100 | |
ElementSplittingDebug | false | boolean | |
DetectMoves | false | boolean | |
MoveAttributeXpath | n/a | string | |
OrphanedWordDetectionEnabled | true | boolean | |
OrphanedWordLengthLimit | 2 | 1 to unlimited | |
OrphanedWordMaxPercentage | 20 | 1 to 100 | |
ChangeGatheringEnabled | true | boolean | |
ModifiedWhitespaceBehaviour | AUTOMATIC | (See API docs) | |
ResultFormat | DELTA | ARBORTEXT_TC FRAMEMAKER_TC OXYGEN_TC XMETAL_TC | |
ModifiedAttributeMode | AUTOMATIC | (See API docs) | |
ModifiedFormatOutput | AUTOMATIC | A B CHANGE CONTENT_GROUP | |
OrderlessPresentationMode | B_DELETES | (See API docs) | |
AttributeChangeMarked | false | boolean | |
XmetalTrackChangesTableChangeMode | DOWN | IGNORE UP | |
FramemakerTrackChangesTableChangeMode | DOWN | IGNORE UP | |
Grouping | true | boolean |
Appendix III - Document Comparator Samples
The Samples section of XML Compare's documentation provides links to all samples and guides, these are designed for use with one or more of XML Compare's comparators. The following list highlights samples of particular relevance to the Document Comparator.