
Managing White Space
Introduction
The processing of input whitespace before comparison is extremely important to get right and the best thing to do depends largely upon what type of XML files you are comparing and what you want to do with the result.
The W3C XML specification talks about how an XML processor should treat whitespace in documents: "An XML processor MUST always pass all characters in a document that are not markup through to the application. A validating XML processor MUST also inform the application which of these characters constitute white space appearing in element content."
When comparing two XML trees, it is important to consider the implications of including whitespace nodes in the comparison. Whitespace nodes can take up a huge percentage of space in an in-memory tree, particularly if the documents were "pretty-printed". This affects not only the memory consumption of the comparison process but also affects the speed and accuracy of comparison. Unless there is a good reason for retaining whitespace in the inputs, it is a good idea to remove it prior to comparison.
When using the LexicalPreservation filter (standard for PipelinedComparatorS9 and DocumentComparator), the PreserveItem IgnorableWhitespace can be used to explicitly exclude or include ignorable whitespace. See the Lexical Preservation Guide for more detail. For further reading see this reference.
Release 8.2 of XML Compare provides enhanced features for managing both ignorable and 'non-ignorable' whitespace. The Enhanced Whitespace Handling guide provides further information on the new features of the lexical preservation and normalization filters, along with a description of the additional built-in filter for inferring whitespace significance.
What kinds of whitespace nodes are there?
Because whitespace has many uses within an XML document, we need to find a way of referring to different types of whitespace nodes so that we can potentially treat them differently. This section will use examples to show where whitespace nodes can occur.
Inter-element whitespace
These whitespace nodes are typically used to pretty-print XML files to make them easier to read. The following example highlights inter-element carriage returns (CR) and tabs (T) that are typically used to pretty print the XML. Note that any whitespace can be used, tabs are often replaced by multiple space characters.

Whitespace in mixed content
An element is said to contain mixed content if it can contain PCDATA and, optionally, element content. This definition occurs in the W3C XML Specification.
Whitespace nodes typically appear in between consecutive elements and are usually significant as they define space in between words. If the highlighted whitespace node in the following example (space shown as _) were to be removed, the two bold words would appear to be joined together in a typical renderer.

It is important to note that PCDATA whitespace nodes also qualify as mixed content whitespace. Because it is not inter-element whitespace, it may need to be treated as significant. The following example highlights space characters (shown as _ characters) that appear in PCDATA-only content:

Please see the mixed content section below to see how these types of whitespace are differentiated by an XML Parser.
Scenarios
As mentioned in the introduction, the best way of handling whitespace depends on what type of XML files you are comparing and what the result file will be used for. Listed below are some typical scenarios along with recommendations on what to do with whitespace.
Data-centric XML
If your XML files are data files as opposed to documents, it is highly likely that almost all whitespace nodes are insignificant. It is also likely that there will be a DTD or XML Schema associated with the files that defines the data format. In this scenario the best practice would be to remove input whitespace using the NormalizeSpace Java filter.
Document-centric XML, viewing/processing changes only
If your XML files are documents, e.g. DocBook, DITA or OpenDocument then some of the whitespace will be significant and some of it won't. Typically, whitespace that occurs where PCDATA is allowed should be treated as significant but other inter-element whitespace should not. If you are processing these files in order to highlight changes, you will probably not be too concerned about how the resultant XML is output, i.e. there is no need to indent or pretty-print. The best approach for this scenario is to remove inter-element whitespace and normalize significant whitespace by setting the 'IgnorableWhitespace' PreserveItem in LexicalPreservation false and using the NormalizeSpace Java filter.
Document-centric XML, compare and continue editing
If you edit your files in an XML view in an XML editor, you will understand that inter-element whitespace is significant for human-readable documents. If you are comparing documents and then continuing to work on the result files in an editor, you will probably want the result whitespace to look as close to the input whitespace as is possible. In this scenario, you will probably not want to use the NormalizeSpace filter but you need to be aware that differences in whitespace nodes will be highlighted in the delta file and, if you are post-processing it with further output filters, you may need to decide how to handle modified whitespace. Please see the handling whitespace differences section below for an example approach.
NormalizeSpace
This filter is a Java implementation of an XML filter that normalizes whitespace and PCDATA nodes that occur in XML documents. The DocumentComparator invokes the NormalizeSpace filter automatically when the ModifiedWhitespaceBehaviour property of ResultReadabilityOptions is set to 'NORMALIZE'. For other comparators, this filter should be added explicitly to the input pipeline when normalization is required.
Normalization is the process of removing inter-element whitespace nodes (known as 'ignorable whitespace') or converting multiple consecutive whitespace characters in a PCDATA node into a single space character. You can read more about the filter in the XML Compare API documentation. It is important to note that, by default, when NormalizeSpace receives a characters() SAX event that contains only whitespace characters, it will ignore it, thus removing it from the input completely. In order for this behaviour to be changed to normalizing the characters rather than removing them, the containing element must be defined as containing mixed content. See the mixed content section for how this can be achieved.
The W3C specification for XPath defines the normalize-space() string function that can be used in XSLT filters for normalizing space on a string. The NormalizeSpace filter follows this definition, except that it does not remove leading and trailing spaces because this can lead to the removal of significant whitespace characters. Consider the string highlighted in the following example:
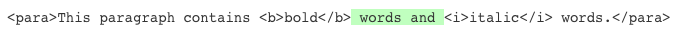
If the leading and trailing spaces were removed from this string, as would be the case if you were to use the normalize-space() function on it, there would no longer be spaces between words that appear in the bold and italic elements before and after it.
Determining whether whitespace nodes are ignorable or significant
The NormalizeSpace filter should be preceded by the built-in XSLT 'whitespace-detection.xsl' filter or a user-defined equivalent (whitespace-detection.xsl should not be added for the DocumentComparator as this is used implicitly). . The responsibility of this filter is to ensure that mixed-content elements (that may contain significant whitespace-nodes) or elements that should be not normalized at all are properly marked.
Treatment of whitespace is determined in the following ways:
When no DTD or XML Schema is loaded and no grammar information has been added by a user-defined filter, whitespace patterns are analysed by 'whitespace-detection.xsl' to determine if whitespace nodes contained within a specific element should be considered significant. Such elements are marked with a 'mixed-content' attribute with the value 'true'.
With a DTD or XML Schema loaded:
When 'PreserveIgnorableWhitespace' = 'true': ignorable whitespace is wrapped with a 'preserve:ignorable' element.
When 'PreserveIgnorableWhitespace' = 'false': ignorable whitespace is stripped at the lexical processing stage.
Irrespective of the ''PreserveIgnorableWhitespace' setting: all elements that may contain text content (whitespace-nodes are significant), will have a 'mixed-content' attribute added with the value 'true'.
xml:space attributes
The NormalizeSpace filter treats xml:space attributes in accordance with their definition in the XML specification. If you want to use normalize space in most of your document but keep all spaces within specific subtrees, you can add the xml:space="preserve" attribute to those elements where you want whitespace to remain untouched, if you don't want these to be persisted in the output you can use deltaxml:space="preserve" attributes instead . Note that xml:space attributes are often added as a default attribute when parsing a document that refers to a DTD or XML Schema with certain elements in document formats, e.g. programlisting in DocBook 4.
Normalizing attribute values
The W3C XML Specification includes a section on attribute value normalization. In order to comply with this, NormalizeSpace leaves attribute values alone. If you want attribute values to be normalized (regardless of whether they were defined as CDATA or NMTOKEN), you can configure NormalizeSpace to do so by passing a value of true to the setnormalizeAttValues() method. Note that when using the DocumentComparator, the NormalizeSpace filter is used internally so this method is not available.
Mixed Content
For NormalizeSpace to correctly handle mixed content whitespace-only nodes (see the definition above), it is important to note that it must be defined correctly. There are four ways of defining whitespace nodes as appearing in mixed content;
define a DTD for the XML format and reference it in a doctype in the document
define an XML Schema for the XML format and reference it with a parser validation feature setting.
automatically infer mixed-content using DocumentComparator or the built-in whitespace-detection.xsl filter
use an attribute in the deltaxml namespace,
deltaxml:mixed-content="true"to mark elements where mixed content can occur
Consider the whitespace node that appears in the following example (marked with _):

The following examples show how to use each of the two options to inform NormalizeSpace to treat this space as mixed content rather than inter-element (ignorable) whitespace and therefore not remove it.
Example 1: Use a DTD
This example uses an inline DTD but the same effect can be achieved using an external document.
CODE
|
Example 2: Use the deltaxml attribute
CODE
|
N.B. The deltaxml:mixed-content attribute only applies to the element on which it appears, it does not apply to child elements. If you want them to be treated as mixed content, you must explicitly add the attribute to them as well.
The example above would typically not be something seen by a user or author of the content. It is possible to dynamically add attributes such as this using an XSLT input filter. We would recommend such filters be created by a mechanistic analysis of a DTD or other schema associated with the content being processed.
Handling Whitespace Differences
The way in which differences in whitespace should be handled is context dependent. The DocumentComparator has a ModifiedWhitespaceBehaviour property (a ResultReadabilityOptions setting) for controlling this. For other comparators a custom filter is required.
For the purposes of this discussion we shall focus on one example. Suppose we have a document where whitespace is being used to indent the XML for readability of multi-line paragraphs, and that we want the existing document's indentation to be kept. In this context, the precise location of the line breaks and indents within two versions of a paragraph may change, which may require us to align a single space with a 'line break' and/or 'indent'. Such changes in whitespace are typically irrelevant and can be removed from the result by a post processing filter. For further reading on indentation see this reference.
Removing changed whitespace from the output appears to be straightforward. All that needs to be done is to identify modified text whose change is only in whitespace and then select either the 'A' or 'B' (old or new) version of the input. However, this approach does not handle the cases where:
Whitespace is explicitly being preserved (e.g. xml:space attribute is set to preserve), and
Insignificant whitespace change occurs in text that contains other significant change.
The first of these cases can be handled by guarding the whitespace modification transformation so that it only happens where whitespace changes are not being preserved. And the second case, can be mitigated by applying the insignificant whitespace change remover before the text groups representing that change have been split up, merged, or removed (e.g. by red-green filtering). This enables modified whitespace text groups to be replaced by either the 'A' or 'B' version of the whitespace text as desired. Note that, in general, it is not 'safe' to convert text groups that contain only 'added' or 'deleted' whitespace, as this space may result in an unmarked word concatenation or split (e.g. 'for' and 'ward' to 'forward' or the reverse).
The following XSLT template can be used to perform the whitespace modification on text groups. The notInsidePreservationSubtree function is used to determine whether this node can have changes in its whitespace removed, and the whitespace-mode variable specifies whether to keep the first or second (i.e. 'A' or 'B') document's whitespace.
CODE
|
Note that in order for such processing to have an affect, the whitespace within the input documents should not be normalized.
Keeping Content Model Information
When elements are marked with either the deltaxml:mixed-content or deltaxml:space attribute, we are helping define their content and how they should be processed. A deltaxml:grammar attribute is also added to the root element to describe where this information came from, it may have the values: 'inferred', 'dtd' or 'schema'. This information is used by the whitespace-detection.xsl and NormalizeSpace filters, but it may also be useful at other stages in the pipeline, or at the serialization stage.
Such attributes in the 'deltaxml' namespace are likely to be removed either within the pipeline (by NormalizeSpace for example) or as part of the clean-up filter. To ensure these attributes are persisted throughout but keep the same behaviour, they can instead be placed in the 'preserve' namespace. This behaviour is controlled by the PreserveContentModel setting of the LexicalPreservationConfig class and also the 'preserve-content-model' parameter of the whitespace-detection.xsl filter, but may also be exploited by custom filters.
Note that preserved 'ContentModel' attributes are kept in the comparison output, even if they were only added to one of the input documents.
An example of how this content model information can be exploited can be found in the built-in 'dx2-deltaxml-folding-html.xsl' filter used to produce the folding DiffReport view. This information helps determine the layout and CSS properties for the HTML rendered view.